Chapter 18 Filtering (Subsetting) Data
In this chapter, we will learn how to filter (subset) cases from a data frame and how to select or remove variables from a data frame. We’ll begin with a conceptual overview of filtering (subsetting) and variable selection/removal. In this chapter, we’ll use the terms “filter” and “subset” interchangeably.
18.1 Conceptual Overview
Filtering data (i.e., subsetting data) is an important data-management process, as it allows us to:
- Select or remove a subset of cases from a data frame based on their scores on one or more variables;
- Select or remove a subset of variables from a data frame.
In this section, we will review logical operators, as it is through the application of logical operators that we will ultimately filter (subset) cases from a data frame.
18.1.1 Review of Logical Operators
When our goal is to select or remove a subset of cases (i.e., observations) from a data frame, we typically do so by applying logical operators. You may already be comfortable with the use of logical operators and expressions like “greater than” (\(>\)), “less than” (\(<\)), “equal to” (\(=\)), “greater than or equal to” (\(\ge\)), and “less than or equal to” (\(\le\)), but you may be less comfortable with the use of the logical “OR” and the logical “AND”. Thus, before we start working with data, let’s do a quick review.
When we wish to apply a single logical statement, our job is relatively straightforward. To keep things simple, let’s focus on a single vector, and we’ll call that vector \(X\). For example, we might choose to select only those cases with scores on \(X\) that are “greater than or equal to” (\(\ge\) or \(>\)\(=\)) 3, thereby retaining scores that are equal to or greater than 3, as highlighted in blue below. In other words, we select only those cases for which their score on \(X\) would be true given the logical statement \(X \ge 3\).
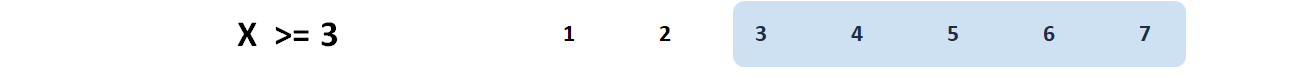
As another example, we might choose to select only those cases with scores on \(X\) that are “less than or equal to” (\(\le\) or \(<\)\(=\)) 5, thereby retaining scores that are equal to or less than 5, as highlighted in red below. In other words, we select only those cases for which their score on \(X\) would be true given the logical statement \(X \le 5\).

If we apply the logical “OR” operator, things get a bit more interesting. The logical “OR” is used when our objective is to select cases based on two logical statements, and if either logical statement is true for a given case, then that case is selected. The logical “OR” is consistent with idea of a mathematical union (\(\cup\)) from Set Theory. As an example, let’s combine the two logical statements from above with the logical “OR” operator. We retain those cases for which their score on \(X\) is “greater than or equal to” 3 or “less than or equal to” 5. Given that \(X\) has possible scores ranging from 1-7, below, we see that this logic retains all cases, as all scores (1-7) would satisfy one or both of the logical statements.

Using the same to logical statements above, let’s replace the logical “OR” with the logical “AND”. The logical “AND” is used when our objective is to select cases based on two logical statements, and if both logical statements are true for a given case, then that case is selected. The logical “AND” is consistent with idea of a mathematical intersection (\(\cap\)) from Set Theory. In this example, we retain only those cases for which their score on \(X\) is “greater than or equal to” 3 and “less than or equal to” 5. Given that \(X\) has possible scores ranging from 1-7, below, we see that this logic retain only cases with scores within the range 3-5, as only scores of 3, 4, or 5 would satisfy both of the logical statements.
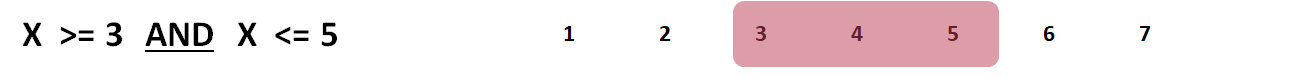
18.2 Tutorial
This chapter’s tutorial demonstrates how to filter (subset) cases from a data frame and how to select or remove variables from a data frame.
18.2.1 Video Tutorial
As usual, you have the choice to follow along with the written tutorial in this chapter or to watch the video tutorial below. Both versions of the tutorial will show you how to filter (subset) data with or without the pipe (%>%) operator. If you’re unfamiliar with the pipe operator, no need to worry: I provide a brief explanation and demonstration regarding their purpose in both versions of the tutorial. Finally, please note that in the chapter supplement you have an opportunity to learn how to filter (subset) cases and select/remove variables using a function from base R, which you may find more intuitive or preferable for other reasons.
Link to video tutorial: https://youtu.be/izVcbPmu0D0
18.2.2 Functions & Packages Introduced
| Function | Package |
|---|---|
str |
base R |
filter |
dplyr |
c |
base R |
as.Date |
base R |
select |
dplyr |
subset |
base R |
18.2.3 Initial Steps
If you haven’t already, save the files called “PersData.csv” and “PerfData.csv” into a folder that you will subsequently set as your working directory. Your working directory will likely be different than the one shown below (i.e., "H:/RWorkshop"). As a reminder, you can access all of the data files referenced in this book by downloading them as a compressed (zipped) folder from the my GitHub site: https://github.com/davidcaughlin/R-Tutorial-Data-Files; once you’ve followed the link to GitHub, just click “Code” (or “Download”) followed by “Download ZIP”, which will download all of the data files referenced in this book. For the sake of parsimony, I recommend downloading all of the data files into the same folder on your computer, which will allow you to set that same folder as your working directory for each of the chapters in this book.
Next, using the setwd function, set your working directory to the folder in which you saved the data file for this chapter. Alternatively, you can manually set your working directory folder in your drop-down menus by going to Session > Set Working Directory > Choose Directory…. Be sure to create a new R script file (.R) or update an existing R script file so that you can save your script and annotations. If you need refreshers on how to set your working directory and how to create and save an R script, please refer to Setting a Working Directory and Creating & Saving an R Script.
Next, read in the .csv data files called “PersData.csv” and “PerfData.csv” using your choice of read function. In this example, I use the read_csv function from the readr package (Wickham, Hester, and Bryan 2024). If you choose to use the read_csv function, be sure that you have installed and accessed the readr package using the install.packages and library functions. Note: You don’t need to install a package every time you wish to access it; in general, I would recommend updating a package installation once ever 1-3 months. For refreshers on installing packages and reading data into R, please refer to Packages and Reading Data into R.
# Install readr package if you haven't already
# [Note: You don't need to install a package every
# time you wish to access it]
install.packages("readr")# Access readr package
library(readr)
# Read data and name data frame (tibble) objects
personaldata <- read_csv("PersData.csv")## Rows: 9 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (4): lastname, firstname, startdate, gender
## dbl (1): id
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## Rows: 6 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (5): id, perf_q1, perf_q2, perf_q3, perf_q4
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## [1] "id" "lastname" "firstname" "startdate" "gender"## [1] "id" "perf_q1" "perf_q2" "perf_q3" "perf_q4"## # A tibble: 9 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 153 Sanchez Alejandro 1/1/2016 male
## 2 154 McDonald Ronald 1/9/2016 male
## 3 155 Smith John 1/9/2016 male
## 4 165 Doe Jane 1/4/2016 female
## 5 125 Franklin Benjamin 1/5/2016 male
## 6 111 Newton Isaac 1/9/2016 male
## 7 198 Morales Linda 1/7/2016 female
## 8 201 Providence Cindy 1/9/2016 female
## 9 282 Legend John 1/9/2016 male## # A tibble: 6 × 5
## id perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 153 3.9 4.8 4.9 5
## 2 125 2.1 1.9 2.1 2.3
## 3 111 3.3 3.3 3.4 3.3
## 4 198 4.9 4.5 4.4 4.8
## 5 201 1.2 1.1 1 1
## 6 282 2.2 2.3 2.4 2.5As you can see from the output generated in your console, on the one hand, the personaldata data frame object contains basic employee demographic information. The variable names include: id, lastname, firstname, startdate, and gender. On the other hand, the personaldata data frame object contains the same id unique identifier variable as the personaldata data frame object, but instead of employee demographic information, this data frame object includes variables associated with quarterly employee performance: perf_q1, perf_q2, perf_q3, and perf_q4.
To make this chapter more interesting (and for the sake of practice), let’s use the full_join function from dplyr (Wickham et al. 2023) to join (merge) the two data frames we just read in (personaldata, performancedata) using the id variable as the key variable. Let’s arbitrarily name the new joined (merged) data frame mergeddf using the <- operator. For more information on joining data, check out the chapter called Joining (Merging) Data.
# Install readr package if you haven't already
# [Note: You don't need to install a package every
# time you wish to access it]
install.packages("dplyr")# Full join (without pipe)
mergeddf <- full_join(personaldata, performancedata, by="id")
# Print joined (merged) data frame object
print(mergeddf)## # A tibble: 9 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 153 Sanchez Alejandro 1/1/2016 male 3.9 4.8 4.9 5
## 2 154 McDonald Ronald 1/9/2016 male NA NA NA NA
## 3 155 Smith John 1/9/2016 male NA NA NA NA
## 4 165 Doe Jane 1/4/2016 female NA NA NA NA
## 5 125 Franklin Benjamin 1/5/2016 male 2.1 1.9 2.1 2.3
## 6 111 Newton Isaac 1/9/2016 male 3.3 3.3 3.4 3.3
## 7 198 Morales Linda 1/7/2016 female 4.9 4.5 4.4 4.8
## 8 201 Providence Cindy 1/9/2016 female 1.2 1.1 1 1
## 9 282 Legend John 1/9/2016 male 2.2 2.3 2.4 2.5Now we have a joined data frame called mergeddf!
18.2.4 Filter Cases from Data Frame
Sometimes we want to select only a subset of cases from a data frame or table. There are different functions that can achieve this end. For example, the subset function filter from base R will do the trick. With that said, the dplyr package (Wickham et al. 2023) offers the filter function which has some advantages (e.g., faster with larger amounts of data), and thus, we will focus on the filter function in this chapter. If you would like to learn how to use the subset function from base R, check out the chapter supplement called Joining (Merging) Data.
In order to properly filter data by cases, we need to know the respective types (classes) of the variables in the data frame. Perhaps the quickest way to find out the type (class) of each variable in the data frame is to use the str (structure) function from base R, and the function’s parentheses, just enter the name of the data frame (mergeddf).
## spc_tbl_ [9 × 9] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ id : num [1:9] 153 154 155 165 125 111 198 201 282
## $ lastname : chr [1:9] "Sanchez" "McDonald" "Smith" "Doe" ...
## $ firstname: chr [1:9] "Alejandro" "Ronald" "John" "Jane" ...
## $ startdate: chr [1:9] "1/1/2016" "1/9/2016" "1/9/2016" "1/4/2016" ...
## $ gender : chr [1:9] "male" "male" "male" "female" ...
## $ perf_q1 : num [1:9] 3.9 NA NA NA 2.1 3.3 4.9 1.2 2.2
## $ perf_q2 : num [1:9] 4.8 NA NA NA 1.9 3.3 4.5 1.1 2.3
## $ perf_q3 : num [1:9] 4.9 NA NA NA 2.1 3.4 4.4 1 2.4
## $ perf_q4 : num [1:9] 5 NA NA NA 2.3 3.3 4.8 1 2.5
## - attr(*, "spec")=
## .. cols(
## .. id = col_double(),
## .. lastname = col_character(),
## .. firstname = col_character(),
## .. startdate = col_character(),
## .. gender = col_character()
## .. )
## - attr(*, "problems")=<externalptr>Note that the id variable is of type integer; the lastname, firstname, startdate, and gender variables are of type character (string); and the perf_q4, perf_q4, perf_q4, and perf_q4 variables are of type numeric. The variable type will have important implications for how use use the filter function from dplyr.
In R, we can apply any one of the following logical operators when filtering our data:
| Logical Operator | Definition |
|---|---|
< |
“less than” |
> |
“greater than” |
<= |
“less than or equal to” |
>= |
“greater than or equal to” |
== |
“equal to” |
!= |
“not equal to” |
| |
“or” |
& |
“and” |
! |
“not” |
To get started, install and access the dplyr package.
I will demonstrate two approaches for applying the filter function from dplyr. The first option uses “pipe(s),” which in R is represented by the %>% operator. The pipe operator comes from a package called magrittr (Bache and Wickham 2022), on which the dplyr is partially dependent. In short, a pipe allows one to more efficiently code/script and to improve the readability of the code/script under certain conditions. Specifically, a pipe forwards the result or value of one object or expression to a subsequent function. In doing so, one can avoid writing functions in which other functions are nested parenthetically. The second option is more traditional and lacks the efficiency and readability of pipes. You can use either approach, and if don’t you want to use pipes, skip to the section below called Without Pipes. For more information on the pipe operator, check out this link: https://r4ds.had.co.nz/pipes.html.
18.2.4.1 With Pipes
Using an approach with pipes, first, use the <- operator to name the filtered data frame that we will create. For this example, I name the new joined data frame filterdf; you could name it whatever you would like. Second, type the name of the first data frame, which we named mergeddf (see above), followed by the pipe (%>%) operator. This will “pipe” our data frame into the subsequent function. Third, either on the same line or on the next line, type the filter function. Fourth, within the function parentheses, type the name of the variable we wish to filter the data frame by, which in this example is gender. Fourth, type a logical operator, which for this example is ==. Fifth, type a value for the filter variable, which in this example is “female”; because the gender variable is of type character, we need to put quotation marks (" ") around the value of the variable that we wish to filter by. Remember, object names in R are case and space sensitive; for instance, gender is different from Gender, and “female” is different from “Female”.
# Filter in by gender with pipe
filterdf <- mergeddf %>% filter(gender=="female")
# Print filtered data frame
filterdf## # A tibble: 3 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 165 Doe Jane 1/4/2016 female NA NA NA NA
## 2 198 Morales Linda 1/7/2016 female 4.9 4.5 4.4 4.8
## 3 201 Providence Cindy 1/9/2016 female 1.2 1.1 1 1Note how the data frame above contains only those cases with “female” as their gender variable designation. The filter worked as expected.
Alternatively, we could filter out those cases in which gender is equal to “female” using the != (not equal to) logical operator.
# Filter out by gender with pipe
filterdf <- mergeddf %>% filter(gender!="female")
# Print filtered data frame
filterdf## # A tibble: 6 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 153 Sanchez Alejandro 1/1/2016 male 3.9 4.8 4.9 5
## 2 154 McDonald Ronald 1/9/2016 male NA NA NA NA
## 3 155 Smith John 1/9/2016 male NA NA NA NA
## 4 125 Franklin Benjamin 1/5/2016 male 2.1 1.9 2.1 2.3
## 5 111 Newton Isaac 1/9/2016 male 3.3 3.3 3.4 3.3
## 6 282 Legend John 1/9/2016 male 2.2 2.3 2.4 2.5Note how cases with gender equal to “female” are no longer in the data frame, while every other case is retained.
Let’s now filter by a variable of type numeric (or integer). Specifically, let’s select those cases in which the perf_q2 variable is greater than (>) 4.0. Because the perf_q2 variable is of type numeric, we don’t use quotation marks (" ") around the value we wish to filter by, which in this case is 4.0.
# Filter by perf_q2 with pipe
filterdf <- mergeddf %>% filter(perf_q2>4.0)
# Print filtered data frame
filterdf## # A tibble: 2 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 153 Sanchez Alejandro 1/1/2016 male 3.9 4.8 4.9 5
## 2 198 Morales Linda 1/7/2016 female 4.9 4.5 4.4 4.8If we wish to filter by two variables, we can apply the logical “or” (|) operator or “and” (&) operator. First, let’s select those cases in which either gender is equal to “female” or perf_q2 is greater than 4.0 using the “or” (|) operator.
# Filter by gender or perf_q2 with pipe
filterdf <- mergeddf %>% filter(gender=="female" | perf_q2>4.0)
# Print filtered data frame
filterdf## # A tibble: 4 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 153 Sanchez Alejandro 1/1/2016 male 3.9 4.8 4.9 5
## 2 165 Doe Jane 1/4/2016 female NA NA NA NA
## 3 198 Morales Linda 1/7/2016 female 4.9 4.5 4.4 4.8
## 4 201 Providence Cindy 1/9/2016 female 1.2 1.1 1 1Watch what happens if we apply the logical “and” (&) operator with the same syntax as above.
# Filter by gender and perf_q2 with pipe
filterdf <- mergeddf %>% filter(gender=="female" & perf_q2>4.0)
# Print filtered data frame
filterdf## # A tibble: 1 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 198 Morales Linda 1/7/2016 female 4.9 4.5 4.4 4.8We can also use the logical “or” (|) operator to select two values of the same variable.
# Filter by two values of firstname with pipe
filterdf <- mergeddf %>% filter(firstname=="John" | firstname=="Jane")
# Print filtered data frame
filterdf## # A tibble: 3 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 155 Smith John 1/9/2016 male NA NA NA NA
## 2 165 Doe Jane 1/4/2016 female NA NA NA NA
## 3 282 Legend John 1/9/2016 male 2.2 2.3 2.4 2.5Or we can select two ranges of values from the same variable using the logical “or” (|) operator, assuming the variable is of type numeric, integer, or date.
# Filter by two ranges of values of perf_q1 with pipe
filterdf <- mergeddf %>% filter(perf_q1<=2.5 | perf_q1>=4.0)
# Print filtered data frame
filterdf## # A tibble: 4 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 125 Franklin Benjamin 1/5/2016 male 2.1 1.9 2.1 2.3
## 2 198 Morales Linda 1/7/2016 female 4.9 4.5 4.4 4.8
## 3 201 Providence Cindy 1/9/2016 female 1.2 1.1 1 1
## 4 282 Legend John 1/9/2016 male 2.2 2.3 2.4 2.5The filter function can also be used to remove multiple specific cases (such as from a unique identifier variable), which might be useful when you’ve identified outliers that need to be removed. As a first step, identify a vector of values that need to be removed. In this example, let’s pretend that cases with id variable values of 198 and 201 no longer work for this company, so they should be removed from the sample. To create a vector of these two values, use the c function like this: c(198,201). Next, because you are now filtering by a vector, you will need to use the %in% operator, which is an operator that instructs R to go through each value of the filter variable (id) and identify instances of 198 and 201 (c(198,201)); if the values match, then those cases are retained. However, because we entered ! in front of the filter variable, this actually reverses our logic and instructs R to remove those cases in which a value of the filter variable matches a value contained in the vector.
# Filter out id of 198 and 201 with pipe
filterdf <- mergeddf %>% filter(!id %in% c(198,201))
# Print filtered data frame
filterdf## # A tibble: 7 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 153 Sanchez Alejandro 1/1/2016 male 3.9 4.8 4.9 5
## 2 154 McDonald Ronald 1/9/2016 male NA NA NA NA
## 3 155 Smith John 1/9/2016 male NA NA NA NA
## 4 165 Doe Jane 1/4/2016 female NA NA NA NA
## 5 125 Franklin Benjamin 1/5/2016 male 2.1 1.9 2.1 2.3
## 6 111 Newton Isaac 1/9/2016 male 3.3 3.3 3.4 3.3
## 7 282 Legend John 1/9/2016 male 2.2 2.3 2.4 2.5Note that in the output above cases with id variable values equal to 198 and 201 are no longer present.
If you remove the ! in front of the filter variable, only cases 198 and 201 are retained.
# Filter in id of 198 and 201 with pipe
filterdf <- mergeddf %>% filter(id %in% c(198,201))
# Print filtered data frame
filterdf## # A tibble: 2 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 198 Morales Linda 1/7/2016 female 4.9 4.5 4.4 4.8
## 2 201 Providence Cindy 1/9/2016 female 1.2 1.1 1 1And if you wanted to remove just a single case, you could use the unique identifier variable (id) and the following script/code.
# Filter out id of 198 with pipe
filterdf <- mergeddf %>% filter(id!=198)
# Print filtered data frame
filterdf## # A tibble: 8 × 9
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 153 Sanchez Alejandro 1/1/2016 male 3.9 4.8 4.9 5
## 2 154 McDonald Ronald 1/9/2016 male NA NA NA NA
## 3 155 Smith John 1/9/2016 male NA NA NA NA
## 4 165 Doe Jane 1/4/2016 female NA NA NA NA
## 5 125 Franklin Benjamin 1/5/2016 male 2.1 1.9 2.1 2.3
## 6 111 Newton Isaac 1/9/2016 male 3.3 3.3 3.4 3.3
## 7 201 Providence Cindy 1/9/2016 female 1.2 1.1 1 1
## 8 282 Legend John 1/9/2016 male 2.2 2.3 2.4 2.5When working with variables of type Date, things can get a bit trickier. When we applied the str function from base R (see above), we found that the startdate variable was read in and joined as a character variable as opposed to a date variable. As such, we need to convert the startdate variable using the as.Date function from base R. First, type the name of the data frame object (mergeddf), followed by the $ operator and the name of whatever you want to call the new variable (startdate2); remember, the $ operator tells R that a variable belongs to (or will belong to) a particular data frame. Second, type the <- operator. Third, type the name of the as.Date function. Fourth, in the function parentheses, as the first argument, enter the as.character function with the name of the data frame object (mergeddf), followed by the $ operator and the name the original variable (startdate) as the sole argument. Fifth, as the second argument in the as.Date function, type format="%m/%d/%Y" to indicate the format for the data variable; note that the capital Y in %Y implies a 4-digit year, whereas a lower case would imply a 2-digit year.
# Convert character startdate variable to the Date type startdate2 variable
mergeddf$startdate2 <- as.Date(as.character(mergeddf$startdate), format="%m/%d/%Y")To verify that the new startdate2 variable is of type date, use the str function from base R, and enter the name of the data frame object (mergeddf) as the sole argument. As you will see, the new startdate2 variable is now of type Date.
## spc_tbl_ [9 × 10] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ id : num [1:9] 153 154 155 165 125 111 198 201 282
## $ lastname : chr [1:9] "Sanchez" "McDonald" "Smith" "Doe" ...
## $ firstname : chr [1:9] "Alejandro" "Ronald" "John" "Jane" ...
## $ startdate : chr [1:9] "1/1/2016" "1/9/2016" "1/9/2016" "1/4/2016" ...
## $ gender : chr [1:9] "male" "male" "male" "female" ...
## $ perf_q1 : num [1:9] 3.9 NA NA NA 2.1 3.3 4.9 1.2 2.2
## $ perf_q2 : num [1:9] 4.8 NA NA NA 1.9 3.3 4.5 1.1 2.3
## $ perf_q3 : num [1:9] 4.9 NA NA NA 2.1 3.4 4.4 1 2.4
## $ perf_q4 : num [1:9] 5 NA NA NA 2.3 3.3 4.8 1 2.5
## $ startdate2: Date[1:9], format: "2016-01-01" "2016-01-09" "2016-01-09" "2016-01-04" ...
## - attr(*, "spec")=
## .. cols(
## .. id = col_double(),
## .. lastname = col_character(),
## .. firstname = col_character(),
## .. startdate = col_character(),
## .. gender = col_character()
## .. )
## - attr(*, "problems")=<externalptr>Now we are ready to filter using the new startdate2 variable. When specify the value of the startdate2 variable by which you wish to filter by, make sure to use the as.Date function once more with the date (formatted as YYYY-MM-DD) in quotation marks (" ") as the sole argument. Here, I filter for those cases in which their startdate2 values are greater than 2016-01-07.
# Filter by startdate2 with pipe
filterdf <- mergeddf %>% filter(startdate2 > as.Date("2016-01-07"))
# Print filtered data frame
filterdf## # A tibble: 5 × 10
## id lastname firstname startdate gender perf_q1 perf_q2 perf_q3 perf_q4 startdate2
## <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <date>
## 1 154 McDonald Ronald 1/9/2016 male NA NA NA NA 2016-01-09
## 2 155 Smith John 1/9/2016 male NA NA NA NA 2016-01-09
## 3 111 Newton Isaac 1/9/2016 male 3.3 3.3 3.4 3.3 2016-01-09
## 4 201 Providence Cindy 1/9/2016 female 1.2 1.1 1 1 2016-01-09
## 5 282 Legend John 1/9/2016 male 2.2 2.3 2.4 2.5 2016-01-0918.2.4.2 Without Pipes
We can also filter using the filter function from the dplyr package without using the pipe (%>%) operator. Note how I simply move the name of the data frame object from before the pipe (%>%) operator to the first argument in the filter function. Everything else remains the same. For simplicity, I don’t display the output below as it is the same as the output as above using pipes. Your decision whether to use a pipe operator is completely up to you.
Let’s filter the mergeddf data frame object such that only those cases for which the gender variable is equal to “female” are retained. Note how we apply the equal to (==) logical operator. A table of logical operators is presented towards the beginning of this tutorial.
# Filter in by gender without pipe
filterdf <- filter(mergeddf, gender=="female")
# Print filtered data frame
filterdfNow let’s filter out those cases in which gender is not equal to “female”. We apply the not equal to (!=) logical operator to do so.
# Filter in by gender without pipe
filterdf <- filter(mergeddf, gender!="female")
# Print filtered data frame
filterdfFilter the data frame such that we retain those cases for which the perf_q2 variable is greater than (>) 4.0. Because the perf_q2 variable is numeric, we don’t put the value 4.0 in quotation marks.
# Filter by perf_q2 without pipe
filterdf <- filter(mergeddf, perf_q2>4.0)
# Print filtered data frame
filterdfUsing the logical “or” operator (|), select those cases for which gender is equal to “female” or for which perf_q2 is greater than 4.0.
# Filter by gender or perf_q2 without pipe
filterdf <- filter(mergeddf, gender=="female" | perf_q2>4.0)
# Print filtered data frame
filterdfUsing the logical “and” operator (&), select those cases for which gender is equal to “female” and for which perf_q2 is greater than 4.0. Note the difference in the resulting filtered data frame.
# Filter by gender and perf_q2 without pipe
filterdf <- filter(mergeddf, gender=="female" & perf_q2>4.0)
# Print filtered data frame
filterdfUsing the logical “or” operator (|), select those cases for which firstname is equal to “John” or for which firstname is equal to “Jane”. In other words, select those individuals whose names are either “John” or “Jane”.
# Filter by two values of firstname without pipe
filterdf <- filter(mergeddf, firstname=="John" | firstname=="Jane")
# Print filtered data frame
filterdfUsing the logical “or” operator (|), select the range of cases for which perf_q1 is less than equal to (<=) 2.5 or for which perf_q1 is greater than or equal (>=) to 4.0.
# Filter by two ranges of values of perf_q1 without pipe
filterdf <- filter(mergeddf, perf_q1<=2.5 | perf_q1>=4.0)
# Print filtered data frame
filterdfThe filter function can also be used to remove multiple specific cases (such as from a unique identifier variable), which might be useful when you’ve identified outliers that need to be removed. As a first step, identify a vector of values that need to be removed. In this example, let’s pretend that cases with id variable values of 198 and 201 no longer work for this company, so they should be removed from the sample. To create a vector of these two values, use the c function like this: c(198,201). Next, because you are now filtering by a vector, you will need to use the %in% operator, which is an operator that instructs R to go through each value of the filter variable (id) and identify instances of 198 and 201 (c(198,201)); if the values match, then those cases are retained. However, because we entered ! in front of the filter variable, this actually reverses our logic and instructs R to remove those cases in which a value of the filter variable matches a value contained in the vector.
# Filter out id of 198 and 201 without pipe
filterdf <- filter(mergeddf, !id %in% c(198,201))
# Print filtered data frame
filterdfOr if you wish to retain only those cases for which the id variable is equal to 198 and 201, drop the not operator (!) from the previous script.
# Filter in id of 198 and 201 without pipe
filterdf <- filter(mergeddf, id %in% c(198,201))
# Print filtered data frame
filterdfYou can also drop specific cases one by one using the not equal to operator (!=) and the a unique identifier value associated with the case you wish to remove. We accomplish the same result as above but use two steps instead. Also, note that in the second step below, the new data frame object (filterdf) is used as the first argument because we want to retain the changes we made in the prior step (i.e., dropping case with id equal to 198).
# Filter in id of 198 without pipe
filterdf <- filter(mergeddf, id!=198)
# Filter in id of 201 without pipe
filterdf <- filter(filterdf, id!=201)
# Print filtered data frame
filterdfWhen working with variables of type Date, things can get a bit trickier. When we applied the str function from base R (see above), we found that the startdate variable was read in and joined as a character variable as opposed to a date variable. As such, we need to convert the startdate variable using the as.Date function from base R. First, type the name of the data frame object (mergeddf), followed by the $ operator and the name of whatever you want to call the new variable (startdate2); remember, the $ operator tells R that a variable belongs to (or will belong to) a particular data frame. Second, type the <- operator. Third, type the name of the as.Date function. Fourth, in the function parentheses, as the first argument, enter the as.character function with the name of the data frame object (mergeddf), followed by the $ operator and the name the original variable (startdate) as the sole argument. Fifth, as the second argument in the as.Date function, type format="%m/%d/%Y" to indicate the format for the data variable; note that the capital Y in %Y implies a 4-digit year, whereas a lower case would imply a 2-digit year. To verify that the new startdate2 variable is of type date, on the next line, use the str function from base R, and enter the name of the data frame object (mergeddf) as the sole argument. As you will see, the new startdate2 variable is now of type Date.
# Convert character startdate variable to the date type startdate2 variable
mergeddf$startdate2 <- as.Date(as.character(mergeddf$startdate), format="%m/%d/%Y")
# Verify that the startdate2 variable is now a variable of type date
str(mergeddf)Now we are ready to filter using the new startdate2 variable. When specify the value of the startdate2 variable by which you wish to filter by, make sure to use the as.Date function once more with the date (formatted as YYYY-MM-DD) in quotation marks (" ") as the sole argument. Here, I filter for those cases in which their startdate2 values are greater than 2016-01-07.
18.2.5 Remove Single Variable from Data Frame
If you just need to remove a single variable from a data frame, using the NULL object in R in conjunction with the <- operator can designate which variable to drop. For example, if we wish to drop the startdate variable from the mergeddf data frame, we simply note that startdate belongs to mergeddf by joining them with $. Next, we set <- NULL adjacent to mergeddf$startdate to indicate that we wish to remove that variable from that data frame.
## # A tibble: 9 × 9
## id lastname firstname gender perf_q1 perf_q2 perf_q3 perf_q4 startdate2
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <date>
## 1 153 Sanchez Alejandro male 3.9 4.8 4.9 5 2016-01-01
## 2 154 McDonald Ronald male NA NA NA NA 2016-01-09
## 3 155 Smith John male NA NA NA NA 2016-01-09
## 4 165 Doe Jane female NA NA NA NA 2016-01-04
## 5 125 Franklin Benjamin male 2.1 1.9 2.1 2.3 2016-01-05
## 6 111 Newton Isaac male 3.3 3.3 3.4 3.3 2016-01-09
## 7 198 Morales Linda female 4.9 4.5 4.4 4.8 2016-01-07
## 8 201 Providence Cindy female 1.2 1.1 1 1 2016-01-09
## 9 282 Legend John male 2.2 2.3 2.4 2.5 2016-01-0918.2.6 Select Multiple Variables from Data Frame
If you wish to select multiple variables from a data frame (and remove all others), the select function from the dplyr package is quite useful and intuitive. Below, I demonstrate how to select multiple variables with and without pipes. If you don’t want to use pipes, feel free to skip down to the section called Without Pipes.
18.2.6.1 With Pipe
Using the pipe (%>%) operator, first, decide whether you want to override an existing data frame or create a new data frame based on our selection; here, I override the mergeddf data frame using the <- operator, which results in mergeddf <-. Second, type the name of the original data frame (mergeddf), followed by the pipe (%>%) operator. Third, type the name of the select function. Fourth, in the parentheses, list the names of the variables you wish to select as arguments; all variables that are not listed will be dropped. Here, we are selecting (to retain) the id, perf_q1, gender, lastname, and firstname variables. Note that the updated date frame includes the selected variables in the order in which you listed them.
# Select multiple variables with pipe
mergeddf <- mergeddf %>% select(id, perf_q1, gender, lastname, firstname)
# Print updated data frame
mergeddf## # A tibble: 9 × 5
## id perf_q1 gender lastname firstname
## <dbl> <dbl> <chr> <chr> <chr>
## 1 153 3.9 male Sanchez Alejandro
## 2 154 NA male McDonald Ronald
## 3 155 NA male Smith John
## 4 165 NA female Doe Jane
## 5 125 2.1 male Franklin Benjamin
## 6 111 3.3 male Newton Isaac
## 7 198 4.9 female Morales Linda
## 8 201 1.2 female Providence Cindy
## 9 282 2.2 male Legend John18.2.7 Remove Multiple Variables from Data Frame
If you wish to remove multiple variables from a data frame, the select function from dplyr will work just fine. I demonstrate how to use this function with and without pipes. If you don’t want to use pipes, feel free to skip down to the section called Without Pipes.
18.2.7.1 With Pipe
Using the pipe (%>%) operator, first, decide whether you want to override an existing data frame or create a new data frame from the subset; here, I override the mergeddf data frame using the <- operator, which results in mergeddf <-. Second, type the name of the original data frame (mergeddf), followed by the pipe (%>%) operator. Third, enter the select function. Fourth, use the c (combine) function with - in front of it to note that you want to select all other variables except the ones listed in the c function.
# Remove multiple variables with pipe
mergeddf <- mergeddf %>% select(-c(lastname, firstname))
# Print updated data frame
mergeddf## # A tibble: 9 × 3
## id perf_q1 gender
## <dbl> <dbl> <chr>
## 1 153 3.9 male
## 2 154 NA male
## 3 155 NA male
## 4 165 NA female
## 5 125 2.1 male
## 6 111 3.3 male
## 7 198 4.9 female
## 8 201 1.2 female
## 9 282 2.2 maleRemoving a single variable can also be done using the select function. To do so, just list a single variable with - in front of it (as the sole argument) to indicate that you wish to drop that variable.
# Remove single variable with pipe
mergeddf <- mergeddf %>% select(-gender)
# Print updated data frame
mergeddf## # A tibble: 9 × 2
## id perf_q1
## <dbl> <dbl>
## 1 153 3.9
## 2 154 NA
## 3 155 NA
## 4 165 NA
## 5 125 2.1
## 6 111 3.3
## 7 198 4.9
## 8 201 1.2
## 9 282 2.218.2.7.2 Without Pipe
If you decide not to use the pipe (%>%) operator, the syntax remains mostly the same except the name of the original data frame object (mergeddf) is moved from before the pipe (%>%) operator to the first argument in the select function. Everything else remains the same.
# Remove multiple variables without pipe
mergeddf <- select(mergeddf, -c(lastname, firstname))
# Print updated data frame
mergeddfAnd here’s the non-pipe equivalent to removing a single variable using this approach.
18.3 Chapter Supplement
In addition to the filter function from the dplyr package covered above, we can use the subset function from base R to subset cases from a data frame and to select cases from a data frame. Because this function comes from base R, we do not need to install and access an additional package like we do with the filter function, which some may prefer or find advantageous. Further, we can also apply the str_detect function from the stringr package with either the subset or the filter function to filter by a text pattern contained within a string (e.g., character) variable.
18.3.1 Video Tutorials
In addition to the written chapter supplement provided below, you can follow along with the following video tutorials to learn more about how to subset cases and select/remove variables using the subset function from base R.
Link to video tutorial: https://youtu.be/iM1e0wxUMrs
Link to video tutorial: https://youtu.be/kNpezEOx70g
18.3.3 Initial Steps
If required, please refer to the Initial Steps section from this chapter for more information on these initial steps.
# Access readr package
library(readr)
# Read data and name data frame (tibble) object
# Note that we will only be reading in one
# data frame object for this supplement
# ones we used in the main part of the chapter
personaldata <- read_csv("PersonalData.csv")## Rows: 8 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (4): lastname, firstname, startdate, gender
## dbl (1): id
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## [1] "id" "lastname" "firstname" "startdate" "gender"## # A tibble: 8 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 153 Sanchez Alejandro 1/1/2016 man
## 2 154 McDonald Ronald 1/9/2016 man
## 3 155 Smith John 1/9/2016 man
## 4 165 Doe Jane 1/4/2016 woman
## 5 111 Newton Isaac 1/9/2016 man
## 6 198 Morales Linda 1/7/2016 woman
## 7 201 Providence Cindy 1/9/2016 woman
## 8 282 Legend John 1/9/2016 man18.3.4 subset Function from Base R
As an alternative to the filter function from the dplyr package, we will learn how to use the subset function from base R to filter cases from a data frame and to select or remove variables from a data frame.
18.3.4.1 Filter (Subset) Cases from Data Frame
We’ll begin by filtering cases from a data frame object. As a reminder, in R, we can apply any one of the following logical operators when filtering cases from a data frame or table object.
| Logical Operator | Definition |
|---|---|
< |
“less than” |
> |
“greater than” |
<= |
“less than or equal to” |
>= |
“greater than or equal to” |
== |
“equal to” |
!= |
“not equal to” |
| |
“or” |
& |
“and” |
! |
“not” |
To filter (subset) cases from a data frame object using the subset function from base R, we will take the following steps:
- We’ll use the
<-assignment operator to name the filtered data frame that we are about to create. For this example, I chose to create a new data frame object (sub_personaldata), which I specified to the left of the<-operator; that being said, you could name the new data frame object whatever you would like. - To the right of the
<-operator, type the name ofsubsetfunction from base R.
- As the first argument in the function, type the name of the data frame we created above (
personaldata). - As the second argument, type the name of the variable we wish to filter the data frame by, which in this example is
genderfollowed by a logical (conditional) argument. For this example, we wish to to retain only those cases in whichgenderis equal to “woman”, and we do so using this logical argumentgender == "woman". Because thegendervariable is of type character, we need to put quotation marks (" ") around the variable value (i.e., text) that we wish to filter by. Remember, object names in R are case and space sensitive; for instance,genderis different fromGender, and “woman” is different from “Woman”.
# Filter (subset) by gender
sub_personaldata <- subset(personaldata, gender == "woman")
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 3 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 165 Doe Jane 1/4/2016 woman
## 2 198 Morales Linda 1/7/2016 woman
## 3 201 Providence Cindy 1/9/2016 womanNote how the data frame above contains only those cases with “woman” as their gender variable designation. The filter worked as expected.
Alternatively, we could filter out (subset out) those cases in which gender is equal to “woman” using the != (not equal to) logical operator. Instead of overwriting the existing data frame object (personaldata), let’s assign the filtered data frame object to a new object that we’ll call sub_personaldata.
# Filter (subset) by gender
sub_personaldata <- subset(personaldata, gender != "woman")
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 5 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 153 Sanchez Alejandro 1/1/2016 man
## 2 154 McDonald Ronald 1/9/2016 man
## 3 155 Smith John 1/9/2016 man
## 4 111 Newton Isaac 1/9/2016 man
## 5 282 Legend John 1/9/2016 manNote how cases with gender equal to “woman” are no longer in the data frame, while every other case is retained.
Let’s now filter (subset) by a variable of type numeric/integer. Specifically, let’s select those cases in which the id variable is greater than (>) 154. Because the id variable consists of type numeric/integer, we won’t use quotation marks (" ") around the value we wish to filter by, which in this case is 154. As we did above, let’s assign the filtered data frame object to an object that we’ll call sub_personaldata; this will overwrite the existing object called sub_personaldata in our R Environment.
# Filter (subset) by id
sub_personaldata <- subset(personaldata, id > 154)
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 5 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 155 Smith John 1/9/2016 man
## 2 165 Doe Jane 1/4/2016 woman
## 3 198 Morales Linda 1/7/2016 woman
## 4 201 Providence Cindy 1/9/2016 woman
## 5 282 Legend John 1/9/2016 manIf we wish to filter (subset) by two variables, we can apply the logical “or” (|) operator or “and” (&) operator. First, let’s select those cases in which either gender is equal to “woman” or id is greater than 154 using the logical “or” (|) operator. This will retain those cases for whom at least one logical statement is true. Once again, let’s assign the filtered data frame object to an object that we’ll call sub_personaldata; this will overwrite the existing object called sub_personaldata in our R Environment.
# Filter (subset) by gender OR id (application of logical OR operator)
sub_personaldata <- subset(personaldata, gender == "woman" | id > 154)
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 5 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 155 Smith John 1/9/2016 man
## 2 165 Doe Jane 1/4/2016 woman
## 3 198 Morales Linda 1/7/2016 woman
## 4 201 Providence Cindy 1/9/2016 woman
## 5 282 Legend John 1/9/2016 manNow watch what happens if we apply the logical “and” (&) operator by keeping everything the same but swapping out the logical “or” (|) operator with the logical “and” (&) operator. This will retain only those cases for whom both logical statements are true.
# Filter (subset) by gender AND id (application of logical AND operator)
sub_personaldata <- subset(personaldata, gender == "woman" & id > 154)
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 3 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 165 Doe Jane 1/4/2016 woman
## 2 198 Morales Linda 1/7/2016 woman
## 3 201 Providence Cindy 1/9/2016 womanWe can also use the logical “or” (|) operator to select two values of the same variable. In this example, we will select cases for whom either firstname is equal to “John” or firstname is equal to “Jane”.
# Filter (subset) by two values of firstname using logical OR
sub_personaldata <- subset(personaldata, firstname == "John" | firstname == "Jane")
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 3 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 155 Smith John 1/9/2016 man
## 2 165 Doe Jane 1/4/2016 woman
## 3 282 Legend John 1/9/2016 manWe can select two ranges of values from the same variable using the logical “or” (|) operator, assuming the variable is of type numeric, integer, or date. In this example, we will retain the cases for whom either logical statement is true: id is less than or equal to 154 or id is greater than or equal to 198.
# Filter (subset) by two ranges of values for id using logical OR
sub_personaldata <- subset(personaldata, id <= 154 | id >= 198)
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 6 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 153 Sanchez Alejandro 1/1/2016 man
## 2 154 McDonald Ronald 1/9/2016 man
## 3 111 Newton Isaac 1/9/2016 man
## 4 198 Morales Linda 1/7/2016 woman
## 5 201 Providence Cindy 1/9/2016 woman
## 6 282 Legend John 1/9/2016 manAlternatively, can select a single range of values within lower and upper bounds from the same variable by using the logical “and” (&) operator, assuming the variable is of type numeric, integer, or date. In this example, we will retain the cases for whom both logical statements are true: id is greater than or equal to 154 and id is less than or equal to 198.
# Filter (subset) by single range of values for id using logical AND
sub_personaldata <- subset(personaldata, id >= 154 & id <= 198)
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 4 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 154 McDonald Ronald 1/9/2016 man
## 2 155 Smith John 1/9/2016 man
## 3 165 Doe Jane 1/4/2016 woman
## 4 198 Morales Linda 1/7/2016 womanThe subset function can also be used to remove multiple specific cases (such as from a unique identifier variable), which might be useful when you’ve identified outliers that need to be removed. As a first step, identify a vector of values that need to be removed. In this example, let’s pretend that cases with id variable values of 198 and 201 no longer work for this company, so they should be removed from the sample. To create a vector of these two values, use the c function like this: c(198,201). Next, because you are now filtering by a vector, you will need to use the %in% operator, which is an operator that instructs R to go through each value of the filter variable (id) and identify instances of 198 and 201 (c(198,201)); if the values match, then those cases are retained. However, because we entered ! in front of the filter variable, this actually reverses our logic and instructs R to remove those cases in which a value of the filter variable matches a value contained in the vector.
# Filter out (subset out) id of 198 and 201
sub_personaldata <- subset(personaldata, !id %in% c(198,201))
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 6 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 153 Sanchez Alejandro 1/1/2016 man
## 2 154 McDonald Ronald 1/9/2016 man
## 3 155 Smith John 1/9/2016 man
## 4 165 Doe Jane 1/4/2016 woman
## 5 111 Newton Isaac 1/9/2016 man
## 6 282 Legend John 1/9/2016 manNote that in the output above cases with id variable values equal to 198 and 201 are no longer present.
If we remove the ! in front of the filter (subset) variable, only cases 198 and 201 are retained.
# Filter in (subset in, select) id of 198 and 201
sub_personaldata <- subset(personaldata, id %in% c(198,201))
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 2 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 198 Morales Linda 1/7/2016 woman
## 2 201 Providence Cindy 1/9/2016 womanWe can also drop specific cases one by one using the not equal to logical operator (!=) and the a unique identifier value associated with the case you wish to remove. We accomplish the same result as above but use two steps instead. Also, note that in the second step below, the new data frame object (sub_personaldata) is used as the first argument in the subset function because we want to retain the changes we made in the prior step (i.e., dropping case with id equal to 198).
# Filter out (subset out) id of 198
sub_personaldata <- subset(personaldata, id != 198)
# Filter out (subset out) id of 201
sub_personaldata <- subset(sub_personaldata, id != 201)
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 6 × 5
## id lastname firstname startdate gender
## <dbl> <chr> <chr> <chr> <chr>
## 1 153 Sanchez Alejandro 1/1/2016 man
## 2 154 McDonald Ronald 1/9/2016 man
## 3 155 Smith John 1/9/2016 man
## 4 165 Doe Jane 1/4/2016 woman
## 5 111 Newton Isaac 1/9/2016 man
## 6 282 Legend John 1/9/2016 manWhen working with variables of type Date, things can get a bit trickier. When we applied the str function from base R (see above), we found that the startdate variable was read in and joined as a character variable as opposed to a date variable. As such, we need to convert the startdate variable using the as.Date function from base R.
- Begin by typing the name of the data frame object (
personaldata), followed by the$operator and the name of whatever you would like to name the new variable (startdate2); remember, the$operator tells R that a variable belongs to (or will belong to) a particular data frame. - Type the
<-assignment operator. - Type the name of the
as.Datefunction.
- As the first argument in the function in the
as.Datefunction, type the name of theas.characterfunction with the name of the data frame object (personaldata), followed by the$operator and the name the original variable (startdate) as the sole argument within theas.characterfunction. Note that we are nesting theas.characterfunction within theas.Datefunction, and due to order of operations, theas.characterfunction will be run first, followed by thestartdatefunction. - As the second argument in the
as.Datefunction, typeformat="%m/%d/%Y"to indicate the format for the data variable; note that the capitalYin%Yimplies a 4-digit year, whereas a lower case would imply a 2-digit year.
# Convert character startdate variable to the Date type startdate2 variable
personaldata$startdate2 <- as.Date(as.character(personaldata$startdate), format="%m/%d/%Y")To verify that the new startdate2 variable is of type Date, use the str function from base R, and type the name of the data frame object (personaldata) as the sole argument. As you will see, the new startdate2 variable is now of type Date.
## spc_tbl_ [8 × 6] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ id : num [1:8] 153 154 155 165 111 198 201 282
## $ lastname : chr [1:8] "Sanchez" "McDonald" "Smith" "Doe" ...
## $ firstname : chr [1:8] "Alejandro" "Ronald" "John" "Jane" ...
## $ startdate : chr [1:8] "1/1/2016" "1/9/2016" "1/9/2016" "1/4/2016" ...
## $ gender : chr [1:8] "man" "man" "man" "woman" ...
## $ startdate2: Date[1:8], format: "2016-01-01" "2016-01-09" "2016-01-09" "2016-01-04" ...
## - attr(*, "spec")=
## .. cols(
## .. id = col_double(),
## .. lastname = col_character(),
## .. firstname = col_character(),
## .. startdate = col_character(),
## .. gender = col_character()
## .. )
## - attr(*, "problems")=<externalptr>Now we are ready to filter (subset) using the new startdate2 variable. When specifying the value of the startdate2 variable by which you wish to filter by, make sure to use the as.Date function once more with the date (formatted as YYYY-MM-DD) in quotation marks (" ") as the sole argument. Here, I select those cases for whom their startdate2 values are greater than 2016-01-07 – or in other words, those cases who started after January 1, 2016.
# Filter (subset) by startdate2
sub_personaldata <- subset(personaldata, startdate2 > as.Date("2016-01-07"))
# Print filtered (subsetted) data frame
print(sub_personaldata)## # A tibble: 5 × 6
## id lastname firstname startdate gender startdate2
## <dbl> <chr> <chr> <chr> <chr> <date>
## 1 154 McDonald Ronald 1/9/2016 man 2016-01-09
## 2 155 Smith John 1/9/2016 man 2016-01-09
## 3 111 Newton Isaac 1/9/2016 man 2016-01-09
## 4 201 Providence Cindy 1/9/2016 woman 2016-01-09
## 5 282 Legend John 1/9/2016 man 2016-01-0918.3.4.2 Select Single Variable from Data Frame
To display a single variable from a data frame in our Console, within the subset function, we can do the following:
- We’ll use the
<-assignment operator to name the data frame that we are about to create. For this example, I chose to create a new data frame object calledtempdf, which I placed to the left of the<-assignment operator; that being said, you could name the new data frame object whatever you would like – or you could overwrite the existing data frame object. - To the right of the
<-operator, type the name ofsubsetfunction from base R.
- As the first argument in the function, type the name of the data frame object from which we wish to select a single variable (
personaldata) - As the second argument, type
select=followed by the name of a single variable (startdate) we wish to select.
# Select only one variable from a data frame (startdate)
tempdf <- subset(personaldata, select=startdate)
# Print data frame
print(tempdf)## # A tibble: 8 × 1
## startdate
## <chr>
## 1 1/1/2016
## 2 1/9/2016
## 3 1/9/2016
## 4 1/4/2016
## 5 1/9/2016
## 6 1/7/2016
## 7 1/9/2016
## 8 1/9/201618.3.4.3 Select Multiple Variables from Data Frame
If our goal is to select multiple variables from a data frame (and remove all others), we can use the subset function as follows. As we did above, name new data frame object using the <- operator, and we will overwrite the data frame object we created above called tempdf. As the first argument in the subset function, type the name of your original data frame object (mergeddf). As the second argument, type select= followed by a vector of variable name you wish to select/retain. The order in which you enter the variable names will correspond to the order in which they appear in the new data frame object. Use the c (combine) function from base R with each variable name you wish to select as arguments separated by commas. Here we select the lastname, firstname, and gender variables.
# Select multiple variables (lastname, firstname, gender)
tempdf <- subset(personaldata, select=c(lastname, firstname, gender))
# Print data frame
print(tempdf)## # A tibble: 8 × 3
## lastname firstname gender
## <chr> <chr> <chr>
## 1 Sanchez Alejandro man
## 2 McDonald Ronald man
## 3 Smith John man
## 4 Doe Jane woman
## 5 Newton Isaac man
## 6 Morales Linda woman
## 7 Providence Cindy woman
## 8 Legend John man18.3.4.4 Remove Single Variable from Data Frame
If you need to remove a single variable from a data frame, you can simply type the minus (-) operator before the name of the variable you wish to remove. Here, we remove the startdate variable.
# Remove one variable from a data frame (startdate)
tempdf <- subset(personaldata, select=-startdate)
# Print data frame
print(tempdf)## # A tibble: 8 × 5
## id lastname firstname gender startdate2
## <dbl> <chr> <chr> <chr> <date>
## 1 153 Sanchez Alejandro man 2016-01-01
## 2 154 McDonald Ronald man 2016-01-09
## 3 155 Smith John man 2016-01-09
## 4 165 Doe Jane woman 2016-01-04
## 5 111 Newton Isaac man 2016-01-09
## 6 198 Morales Linda woman 2016-01-07
## 7 201 Providence Cindy woman 2016-01-09
## 8 282 Legend John man 2016-01-0918.3.4.5 Remove Multiple Variables from Data Frame
If you wish to remove multiple variables from a data frame, you can apply the same syntax as you did when selecting multiple variables, except insert a minus (-) operator in from the of the c function. This tells the function to not select those variables. Here, we remove the lastname and firstname variables from the personaldata data frame object and assign the resulting data frame to an object called tempdf.
# Remove multiple variables (lastname, firstname)
tempdf <- subset(personaldata, select= -c(lastname, firstname))
# Print data frame
print(tempdf)## # A tibble: 8 × 4
## id startdate gender startdate2
## <dbl> <chr> <chr> <date>
## 1 153 1/1/2016 man 2016-01-01
## 2 154 1/9/2016 man 2016-01-09
## 3 155 1/9/2016 man 2016-01-09
## 4 165 1/4/2016 woman 2016-01-04
## 5 111 1/9/2016 man 2016-01-09
## 6 198 1/7/2016 woman 2016-01-07
## 7 201 1/9/2016 woman 2016-01-09
## 8 282 1/9/2016 man 2016-01-0918.3.5 Filter by Pattern Contained within String
In some cases, we may wish to filter cases from a data frame object based on a pattern contained within a string (i.e., text, characters). For example, using the personaldata data frame object we created above, perhaps we would like to select those cases for which their firstname string (i.e., value) contains a capital (“J”). To do so, we can use the str_detect function from the stringr package (Wickham 2019) within either the subset function from base R or the filter function from the dplyr package.
To get started, make sure that you have installed and accessed the stringr package.
# Install stringr package if you haven't already
# [Note: You don't need to install a package every
# time you wish to access it]
install.packages("stringr")Given that this chapter supplement has focused thus far on the subset function from base R, let’s continue to use that function, but please note that you could just as easily use the filter function from the dplyr package.
- Using the
<-operator, we’ll assign the resulting subset data frame to an object that I’m callingsub_personaldata. - To the right of the
<-operator, type the name of thesubsetfunction
- As the first argument in the
subsetfunction, type the name of the original data frame object that we’ve been working with calledpersonaldata. - As the second argument, type the name of the
str_detectfunction. As the first argument within thestr_detectfunction, type the name of the variable we wish to filter by, which in this example isfirstname; as the second argument and within quotation marks (" "), type a pattern you would like to detect within text strings from thefirstnamevariable. For this example, let’s detect any text string containing an uppercase “J” while noting that case sensitivity matters (e.g., “J” vs. “j”). In other words, we are filtering the data frame such that we will retain only those cases for which theirfirstnamevariable text strings (i.e., values) contain an uppercase “J”.
# Select cases for which firstname variable contains a "J"
# Note that case sensitivity matters (e.g., "j" vs. "J")
sub_personaldata <- subset(personaldata, str_detect(firstname, "J"))Now let’s print the new data frame object we created.
## # A tibble: 3 × 6
## id lastname firstname startdate gender startdate2
## <dbl> <chr> <chr> <chr> <chr> <date>
## 1 155 Smith John 1/9/2016 man 2016-01-09
## 2 165 Doe Jane 1/4/2016 woman 2016-01-04
## 3 282 Legend John 1/9/2016 man 2016-01-09