Chapter 24 Describing Employee Demographics Using Descriptive Statistics
In this chapter, we will learn about how descriptive statistics can be used to describe employee-demographic variables. To determine which type of descriptive statistics is appropriate for a given variable, we will learn about measurement scales and how to distinguish from a construct and a measure. Finally, we’ll conclude with a tutorial.
24.1 Conceptual Overview
In this section, we’ll review the four different types of measurement scales (i.e., nominal, ordinal, interval, ratio), the distinctions between constructs, measures, and measurement scales, and different types of descriptive statistics (e.g., counts, measures of central tendency, measures of dispersion).
24.1.1 Review of Measurement Scales
When determining what type of descriptive statistics is appropriate for summarizing data contained within a particular variable, it is important to determine the measurement scale of the variable. Measurement scale (i.e., scale of measurement, level of measurement) refers to the type of information contained within a vector of data (e.g., variable), and the four measurement scales are: nominal, ordinal, interval, and ratio.
24.1.1.1 Nominal
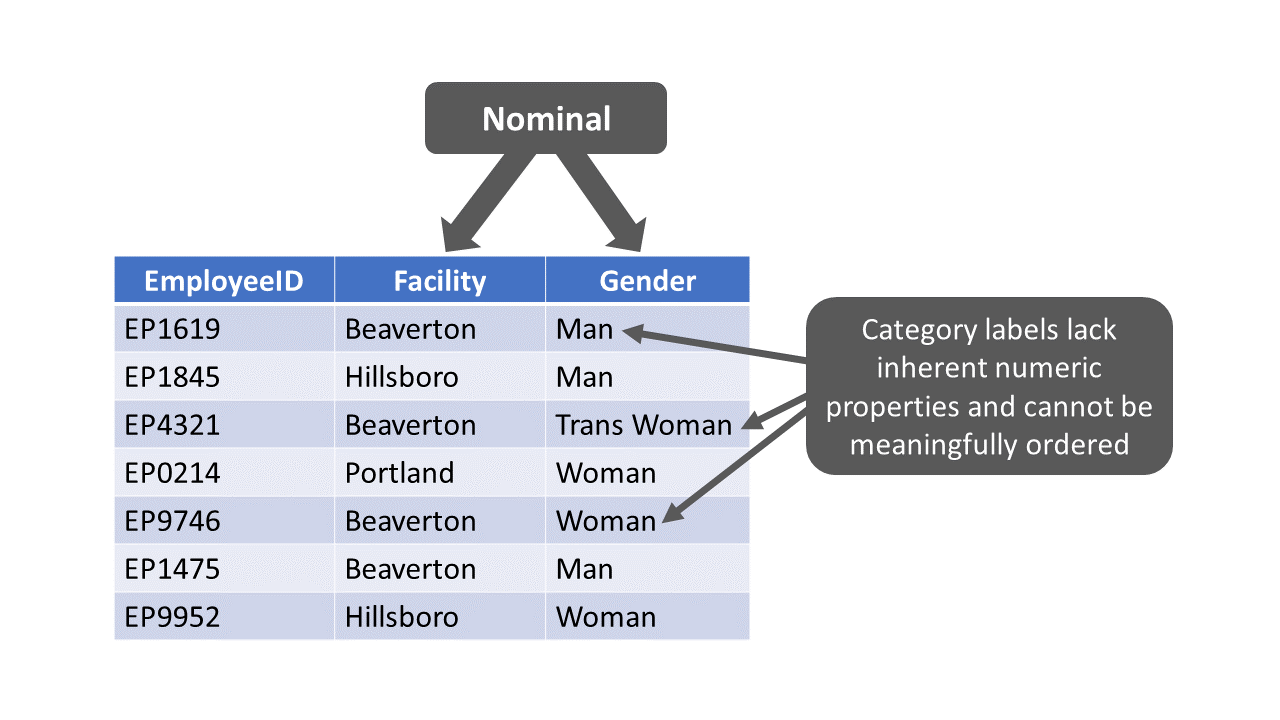
Variables with a nominal measurement scale have different category labels, which are sometimes referred to as levels. The category labels, however, do not have any inherent numeric properties. As an example, let’s operationalize gender identity as having a nominal measurement scale, such that gender identity includes the following category labels: agender, man, nonbinary, trans man, trans woman, and woman. These category labels do not have any inherent numeric values, and although we could assign numeric values to the gender identity category labels (e.g., agender = 1, man = 2, nonbinary = 3, etc.), doing so wouldn’t imply that one category label has a higher value than another. Variables with a nominal measurement scale are sometimes referred to as categorical variables.
24.1.1.2 Ordinal
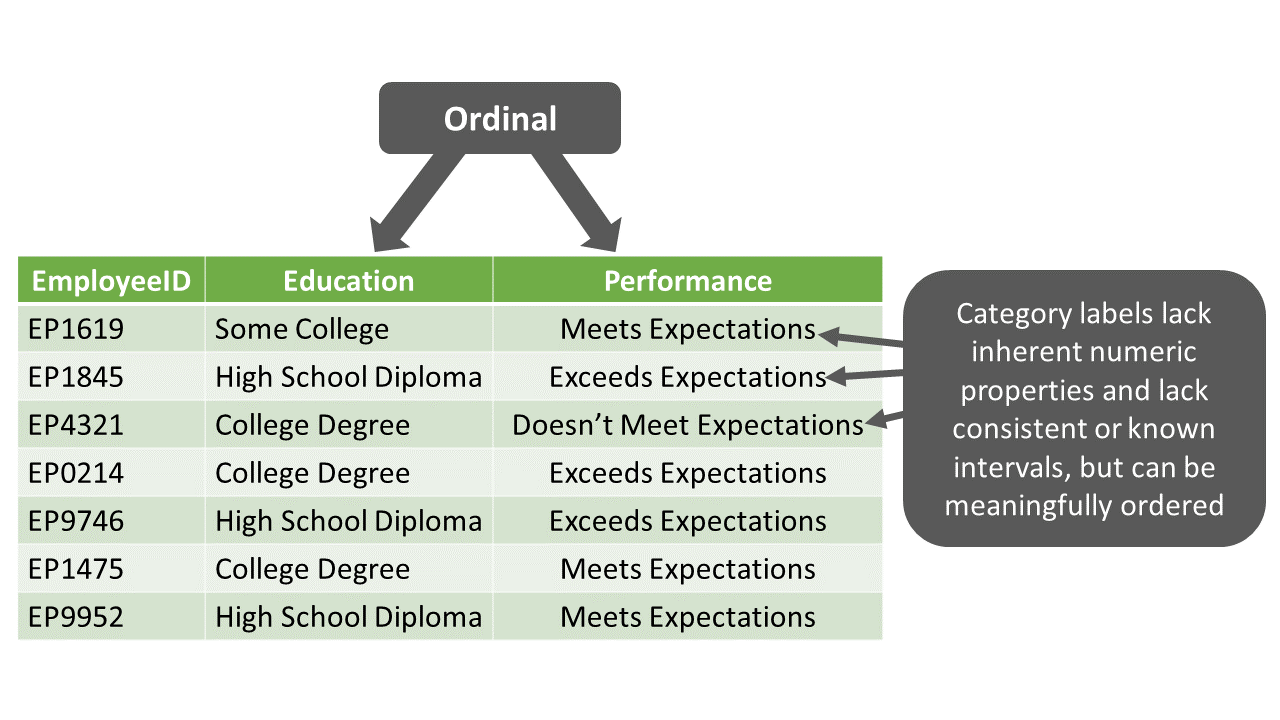
Like variables with a nominal measurement scale, variables with an ordinal measurement scale are a specific type of categorical variable; however, unlike nominal variables, the category labels (i.e., levels) associated with ordinal variables can be ordered or ranked in a meaningful way. It should be noted that the gaps – or intervals – between categorical labels of an ordinal variable are unknown; in other words, we can’t quantify the exact difference between adjacent category labels (i.e., levels). For example, let’s operationalize employee education levels with the following ordered category labels: high school diploma, some college, and college degree. That is, completing some portion of a college degree is a higher level of education than earning a high school diploma, and completing a college degree is a higher level of education than completing some portion of a college degree. We don’t know, though, the size of the interval between earning a high school diploma and completing some college, and between some completing some college and earning a college degree; thus, as operationalized in this example, employee education level demonstrates an ordinal measurement scale (as opposed to an interval measurement scale, which is described in the following section).
A controversial example of an ordinal measurement scale is any type of Likert (or Likert-type) scale or response format. Examples of Likert scales include agreement response formats (e.g., Strongly Disagree, Disagree, Neither Disagree Nor Agree, Agree, Strongly Agree) and frequency response formats (e.g., Never, Rarely, Sometimes, Always). Likert scales are commonly used in employee surveys; for example, survey respondents might be asked to indicate their level of agreement with the following survey item that is designed to assess job satisfaction: “In general, I am satisfied with my job.” Just like any variable with an ordinal measurement scale, we don’t know the exact quantitative intervals between adjacent category labels (i.e., response options) on a Likert scale. Nonetheless, in the social sciences, it is relatively common for analysts to apply numerical values to the ordered category labels on a Likert scale (e.g., 1 = Strongly Disagree, 2 = Disagree, 3 = Neither Disagree Nor Agree, 4 = Agree, 5 = Strongly Agree). After adding these numerical values, the analysts often treat Likert scales as though they were interval measurement scales for the purposes of data analysis, particularly when composite variables (i.e., overall scale score variables) are created by summing or averaging respondents’ scores across multiple survey items.
24.1.1.3 Interval
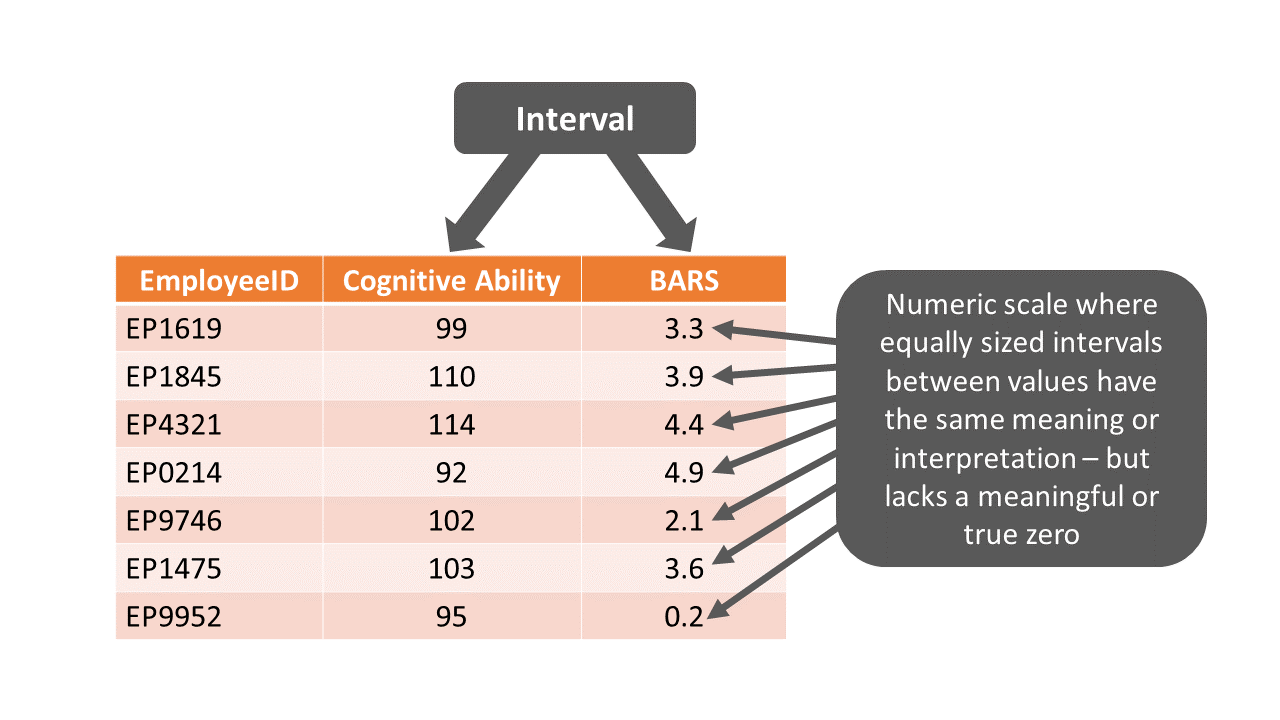
Variables with an interval measurement scale have a numeric scale (e.g., have inherent numeric values), and not only is there an order to the numeric values, equally sized intervals between values have the same meaning or interpretation – hence, the term interval measurement scale. With all that being said, interval variables lack a true or meaningful zero value; in other words, a value of zero is an arbitrary point on the scale – if it even appears in the possible range of values in the first place. Variables with an interval measurement scale are sometimes referred to as continuous variables. As an example, suppose we purchase a cognitive ability (i.e., intelligence) test that we plan to administer to job applicants. Let’s now imagine that this test operationalizes cognitive ability, such that scores can range from 0 to 200, where 100 indicates the average level of cognitive ability in the population. Further, the test is designed such that every 1-point interval holds the same interpretation and is of equal quantitative size when compared to other 1-point intervals on the scale. For instance, let’s imagine that the 1-point interval between 78 and 79 has the same meaning (and quantitative size) as the 1-point interval between 110 and 111. In other words, equally sized intervals between values have the same meaning or interpretation in terms of incremental differences in cognitive ability. Even though this cognitive ability test can produce a score of zero, the zero value is not meaningful, as it does not imply the absence of cognitive ability; rather, it just indicates the lowest point on the numeric scale used to assess cognitive ability happens to be zero, making the zero point on the scale somewhat arbitrary.
24.1.1.4 Ratio
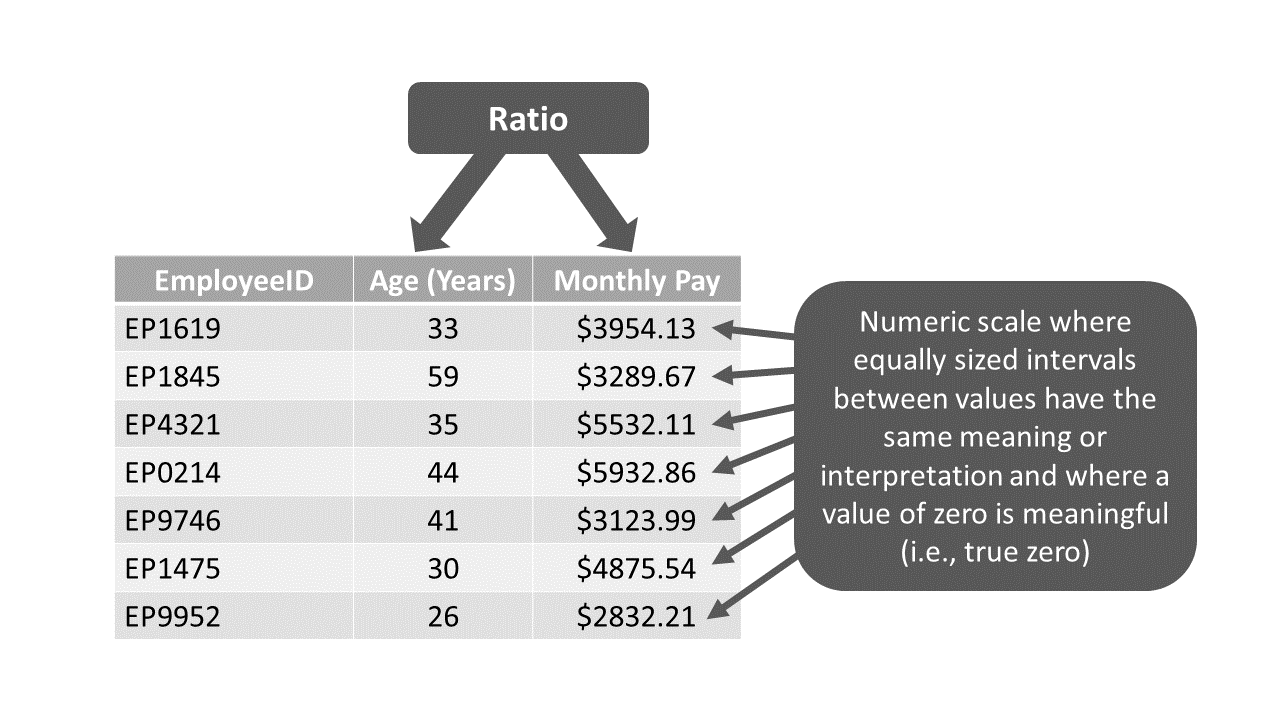
Like variables with an interval measurement scale, variables with a ratio measurement scale are a specific type of continuous variable, as they have a numeric scale in which equally sized intervals between values have the same meaning or interpretation. Unlike interval variables, however, ratio variables have a true and meaningful zero value, such that zero indicates the absence of the construct being measured. Common examples of variables with a ratio measurement scale include those that measure (elapsed) time, where time is measured in standardized units like seconds, minutes, hours, days, months, years, decades, or centuries. Equally sized intervals between various time points have the same meaning, and a time of zero implies the absence of time having elapsed. In organizational settings, we often measure employee age and tenure as numeric elapsed time since a prior date. Because there is a true zero associated with ratio measurement scales, we can make statements like “this individual is twice as old as that individual” or “this individual has worked here one third as long as that individual.” Finally, I should note even if we do not observe a true-zero value in our acquired data, a variable can still have a ratio measurement scale. What matters is whether the scale used to measure the construct in question has a possible true-zero value. Using the example of employee age, we can safely assume that we won’t observe any employees who have an age of exactly zero years; however, because age is measured as a standardized unit of time (i.e., years), we know that when measuring time in this way a value of zero years does exist on this scale – and it it would indicate the absence of time having passed. That is, a value of zero could hypothetically indicate the lack of time having passed since the exact moment of a person’s birth. In sum, even if we don’t observe a zero score in our data, a variable can still be classified as having a ratio measurement scale, so long as the scale used to measure the underlying construct could theoretically include a true or meaningful zero value.
24.1.2 Constructs, Measures, & Measurement Scales
Importantly, we use measures to assess constructs (i.e., concepts), and often there are different ways in which we can measure or operationalize the same construct. Consequently, different measures might have a different measurement scale, even though they are each designed to assess the same construct. For example, if wish to assess the construct of job performance for sales professionals, we could have supervisors rate employee performance using a three-point scale, ranging from “Does Not Meet Expectations” to “Meets Expectations” to “Exceeds Expectations,” which could be described as an ordinal measurement scale. Alternatively, we might also assess the construct of job performance for sales professionals based on how much revenue they generate (in US dollars), which could be described as a ratio measurement scale.
24.1.3 Types of Descriptive Statistics
Link to conceptual video: https://youtu.be/WCC4IXavits
Once we have determined the measurement scale of a variable, we’re ready to choose an appropriate type of descriptive statistics to summarize the data associated with that variable. Descriptive statistics are used to describe the characteristics of a sample drawn from a population; often, when dealing with data about human beings in organizations, it’s not feasible to attain data for the entire population, so instead we settle for what is hopefully a representative sample of individuals from the focal population. Common types of descriptive statistics include counts (i.e., frequencies), measures of central tendency (e.g., mean, median, mode), and measures of dispersion (e.g., variance, standard deviation, interquartile range). Note that descriptive statistics are not tests of statistical significance; for tests of statistical significance, we need to look to inferential statistics (e.g., independent-samples t-test, multiple linear regression). When we analyze employee demographic data, for example, we often compute descriptive statistics like the number of employees who identify with each race/ethnicity category or the average employee age and standard deviation. It’s important to remember that descriptive statistics are, well, descriptive. That is, they help us summarize characteristics of a sample, which is why they are sometimes referred to as summary statistics. As discussed in the chapter on the Data Analysis phase of the HR Analytics Project Life Cycle, descriptive statistics are a specific type of descriptive analytics, as they summarize data that were collected in the past.
Broadly speaking, when describing just a single variable (i.e., applying univariate descriptive statistics), we can distinguish between descriptive statistics that are appropriate for describing categorical versus continuous variables, where categorical variables have a nominal or ordinal measurement scale and continuous variable have an interval or ratio measurement scale. Often, counts (i.e., frequencies) are used to describe data associated with a categorical variable, and measures of central tendency and dispersion are used to describe data associated with a continuous variable.
24.1.3.1 Counts
Counts are useful descriptive statistics when a variable has a nominal or ordinal measurement scale. Counts are also referred to as frequencies, so I’ll use those two terms interchangeably. As an added benefit, counts tend to be understood by a broad audience, as they simply refer to counting or tallying how many instances of each discrete instances of a category label (i.e., level) of a nominal or ordinal variable have occurred. In fact, sometimes it can be quite amazing what insights we can gleaned just by counting things. A common example of counts in the HR context is headcount by department, facility, or unit. Imagine if you will an organization with facilities in three locations: Beaverton, Hillsboro, and Portland. After tallying up how many employees work at each location, we might find that 15 work at the Beaverton facility, 5 at the Hillsboro facility, and 10 at the Portland facility. In this example, “Beaverton,” “Hillsboro,” and “Portland” are our category labels for this nominal variable, and the values 15, 5, and 10, respectively, are the counts associated with each of those category labels.
24.1.3.2 Measures of Central Tendency & Dispersion
Measures of central tendency (e.g., mean, median, mode) summarize the center or most common scores from a distribution of numeric scores, whereas measures of dispersion (e.g., variance, standard deviation, range, interquartile range) summarize variation in numeric scores. Typically, one would apply these specific types of descriptive statistics to describe or summarize variables that have an interval or ratio measurement scale. For example, we might compute the median pay (in US dollars) and the interquartile range in pay for a sample of workers, where pay in this example has a ratio measurement scale.
In some instances, however, numeric values could be assigned to category labels of a variable that can be most accurately described as having an ordinal measurement scale – and upon doing so, the variable might be reclassified as having an interval measurement scale. Such a numeric conversion from ordinal to ratio allows for measures of central tendency and dispersion to be computed. For example, a variable with five Likert responses options ranging from “Strongly Disagree” to “Strongly Agree” would technically have an ordinal measurement scale because there are unknown intervals between each of the levels (i.e., category labels); in other words, the interval distance between “Strongly Disagree” and “Disagree” might not be equal to the interval distance between “Disagree” and “Neither Disagree Nor Agree”. Yet, in order to perform certain analyses, sometimes such variables are reconceptualized as having equal intervals and thus having an interval measurement scale. To do so, we would typically assign numeric values to each of the Likert response options, such as 1 = “Strongly Disagree” and 5 = “Strongly Agree” – which gives the illusion of equal intervals. Perhaps a more compelling case for treating a variable with Likert responses as a having an interval measurement scale is when we create a composite variable (i.e., overall scale score) based on the sum or average of scores from multiple Likert variables (e.g., multiple survey items from a measure).
24.1.4 Sample Write-Up
Based on data stored in the organization’s HR information system, we sought out to describe the organization’s employee demographics. The employee gender and race/ethnicity variables have nominal measurement scales, and thus we computed counts to describe these variables. Specifically, 321 employees identified as women, 300 as men, 25 as nonbinary, 8 as trans women, and 7 as trans men. Further, 192 employees identified as Hispanic/Latino, 145 as White, 132 as Asian, 119 as Black, 40 as Native American, and 33 as Native Hawaiian. Given that employee age was measured in years since birth, we classified the variable as having a ratio measurement scale, meaning that measures of central tendency and dispersion would be appropriate for describing the variable. We found that employee ages were normally distributed, and that the average employee age was 42.13 years with a standard deviation of 7.71, indicating that roughly two-thirds of employees’ ages fall between 34.42 and 49.84 years.
24.2 Tutorial
This chapter’s tutorial demonstrates how to compute various types of descriptive statistics and how to present the findings visually.
24.2.1 Video Tutorials
As usual, you have the choice to follow along with the written tutorial in this chapter or to watch one of the following video tutorials below. Note that in the videos below, I show how to read in the data using the read.csv function from base R, whereas in the written tutorial portion of this chapter, I show how to read in the data using the read_csv function from the readr package.
Link to video tutorial: https://youtu.be/Xg0wiBofjCU
Link to video tutorial: https://youtu.be/10jYstRPDAU
24.2.2 Functions & Packages Introduced
| Function | Package |
|---|---|
table |
base R |
levels |
base R |
factor |
base R |
c |
base R |
barplot |
base R |
pie |
base R |
colors |
base R |
abline |
base R |
hist |
base R |
boxplot |
base R |
c |
base R |
mean |
base R |
median |
base R |
var |
base R |
sd |
base R |
min |
base R |
max |
base R |
range |
base R |
IQR |
base R |
quantile |
base R |
summary |
base R |
24.2.3 Initial Steps
If you haven’t already, save the file called “employee_demo.csv” into a folder that you will subsequently set as your working directory. Your working directory will likely be different than the one shown below (i.e., "H:/RWorkshop"). As a reminder, you can access all of the data files referenced in this book by downloading them as a compressed (zipped) folder from the my GitHub site: https://github.com/davidcaughlin/R-Tutorial-Data-Files; once you’ve followed the link to GitHub, just click “Code” (or “Download”) followed by “Download ZIP”, which will download all of the data files referenced in this book. For the sake of parsimony, I recommend downloading all of the data files into the same folder on your computer, which will allow you to set that same folder as your working directory for each of the chapters in this book.
Next, using the setwd function, set your working directory to the folder in which you saved the data file for this chapter. Alternatively, you can manually set your working directory folder in your drop-down menus by going to Session > Set Working Directory > Choose Directory…. Be sure to create a new R script file (.R) or update an existing R script file so that you can save your script and annotations. If you need refreshers on how to set your working directory and how to create and save an R script, please refer to Setting a Working Directory and Creating & Saving an R Script.
Next, read in the .csv data file called “employee_demo.csv” using your choice of read function. In this example, I use the read_csv function from the readr package (Wickham, Hester, and Bryan 2024). If you choose to use the read_csv function, be sure that you have installed and accessed the readr package using the install.packages and library functions. Note: You don’t need to install a package every time you wish to access it; in general, I would recommend updating a package installation once ever 1-3 months. For refreshers on installing packages and reading data into R, please refer to Packages and Reading Data into R.
# Install readr package if you haven't already
# [Note: You don't need to install a package every
# time you wish to access it]
install.packages("readr")# Access readr package
library(readr)
# Read data and name data frame (tibble) object
demo <- read_csv("employee_demo.csv")## Rows: 30 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (3): EmpID, Facility, Education
## dbl (2): Performance, Age
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## [1] "EmpID" "Facility" "Education" "Performance" "Age"## [1] 30## # A tibble: 30 × 5
## EmpID Facility Education Performance Age
## <chr> <chr> <chr> <dbl> <dbl>
## 1 EE123 Beaverton College Degree 3.8 25
## 2 EE124 Beaverton Some College 9 30
## 3 EE125 Portland High School Diploma 8.3 32
## 4 EE126 Beaverton Some College 9.8 28
## 5 EE127 Beaverton Some College 5.7 30
## 6 EE128 Beaverton College Degree 8.2 30
## 7 EE129 Beaverton College Degree 7.3 28
## 8 EE130 Beaverton College Degree 7.7 28
## 9 EE131 Portland Some College 6.3 28
## 10 EE132 Hillsboro Some College 8.4 27
## # ℹ 20 more rowsThe demo data frame object contains five variables. EmpID, Facility, Education, Performance, and Age. The EmpID variable is the employee unique identifier, and in this data frame, each row corresponds to a unique employee. The Facility variable contains the name of the facility where each employee works. The Education variable includes the highest level of education each employee attained (i.e., High School Diploma, Some College, College Degree). The Performance variable includes the employees’ annual performance scores (as derived by a proprietary algorithm), where a score of 0.0 would indicate exceptionally low job performance and a score of 10 would indicate exceptionally high job performance. The Age variable includes employees’ age (in years).
24.2.4 Determine the Measurement Scale
As described above, we have four employee-demographic variables at our disposal in the data frame object we named demo: Facility, Education, Performance, and Age. Now it’s time to determine which measurement scale best describes each variable – and spoiler alert: These four variables correspond to nominal, ordinal, interval, and ratio measurement scales respectively. Below, I describe why a particular measurement scale maps onto each variable.
By viewing our the data frame object called demo using the print, head, or View functions (as show above in the Initial Steps), we can see that the Facility variable consists of the following categories (i.e., levels): Beaverton, Hillsboro, and Portland. These categories do not have inherent numeric properties, and they can’t be ordered meaningfully given that they just represent different facility locations for this fictitious organization. Given all that, the Facility variable can best be described as having a nominal measurement scale.
The Education variable contains three levels (i.e., categories): High School Diploma, Some College, and College Degree. These three discrete categories do not have inherent numeric properties but can be ordered in terms of a conventional educational progression, where earning a high school diploma would be the lowest level and earning a college degree would be the highest level (of the three). Furthermore, although the three variable levels can be ordered, they do not necessarily have equal intervals between the levels; in other words, the distance (e.g., time) between a high school diploma and completing some college is not necessarily the same as the distance between completing some college and a college degree. Given all of those characteristics, the Education variable in these data can best be described as having an ordinal measurement scale.
The Performance variable includes the annual performance score for each employee (as derived from a proprietary algorithm), where a score of 0.0 would indicate exceptionally low job performance and a score of 10 would indicate exceptionally high job performance. We can assume in this case that intervals between integers are equal, such that the distance between scores of 1 and 2 is the same as the distance between scores 2 and 3; however, because a value of zero (0.0) does not indicate the absence of performance for this variable (but rather exceptionally low job performance), we must conclude that it has an interval measurement scale as opposed to a ratio measurement scale.
Finally, the Age variable includes the age of each employee measured in years. Because Age has ordered numeric values and because there are equal intervals between years as a standard measure of time, we can conclude that the variable does not have a nominal or ordinal measurement scale. What’s more, hypothetically, a value of zero when measuring something in years would imply the absence of years – which is to say Age as measured in years has a meaningful zero value. Given all that, the Age variable can be most accurately described as having a ratio measurement scale.
24.2.5 Describe Nominal & Ordinal (Categorical) Variables
We can describe variables with nominal or ordinal measurement scales by computing counts (i.e., frequencies) and by creating univariate bar charts (or pie charts), and we’ll work through each of these descriptive approaches in the following sections.
24.2.5.1 Compute Counts & Frequencies
Fortunately, it’s quite easy to run counts in R, and we’ll begin by running counts for the Facility variable. One of the simplest approaches is to use the table function from base R. As the sole parenthetical argument, just type the name of the data frame object (demo) followed by the $ operator and the name of the variable that belongs to that data frame object (Facility).
##
## Beaverton Hillsboro Portland
## 15 5 10As we can see, 15 employees work at the Beaverton facility, 5 at the Hillsboro facility, and 10 at the Portland facility. Simply put, the most employees work in Beaverton, followed by Portland and Hillsboro. Of course, we also would hope that these data are accurate and timely, and point-in-time headcount data in organizations can be surprisingly difficult to estimate accurately in some organizations, but that’s a story for another time.
Because we have classified the Education variable as ordinal, we want to make sure that it has ordered levels. That is, High School Diploma should be the lowest level and College Degree should be the highest. To check to see if the variable is a factor with ordered levels, we can apply the levels function from base R and, as the sole parenthetical argument, type the name of the data frame object (demo) followed by the $ operator and the name of the variable that belongs to that data frame object (Education).
## NULLRunning the levels function for the Education variable returns NULL, which indicates that this variable is not a factor variable with ordered levels. Never fear, we can fix that by using the factor function from base R.
To convert the Education variable to an ordered factor variable, we will overwrite the existing Education variable from the demo data frame object. Thus, we will start by typing the name of the data frame object (demo) followed by the $ operator and the name of the variable (Education), and to the right, we will type the <- operator so that we can perform the variable assignment. To the right of the <- operator, we will type the name of the factor function. As the first argument, we will type the name of the data frame object (demo) followed by the $ operator and the name of the variable (Education). As the second argument, we will type ordered=TRUE to signify that this variable will have ordered levels. As the third argument, we’ll type levels= followed by a vector of the variable levels in ascending order. Note that we use the c (combine) function from base R to construct the vector, and we need to put each level within quotation marks (" ").
# Convert Education variable to ordered factor
demo$Education <- factor(demo$Education, ordered=TRUE,
levels=c("High School Diploma",
"Some College",
"College Degree"))Now that we’ve converted the Education variable to an ordered factor variable, let’s verify that we did so correctly by running the same levels function that we did above.
## [1] "High School Diploma" "Some College" "College Degree"Instead of NULL, now we see the levels of the variable in ascending order. Good for us!
With the Education variable now an ordered factor, it now makes sense to run the table function to compute the counts.
##
## High School Diploma Some College College Degree
## 4 15 11Descriptively, we see that the most people completed some college (15), followed closely by 11 people who completed a full college degree. Relatively few employees in this sample had just a high school diploma (4).
24.2.5.2 Create Data Visualizations
When interpreting descriptive statistics, it’s often useful to create some kind of data visualization to display the findings in a pictorial or graphical format. A bar chart is a simple data visualization that many potential audience members will be familiar with, making it a good choice. In addition, when the different categories (e.g., levels) are mutually exclusive and sum to a whole, we might also choose to create a pie chart. We’ll begin by creating a bar chart for the Facility variable and follow that up with creating a pie chart for the Education variable – though, we just as easily could make a bar chart for the Education variable and a pie chart for the Facility variable.
Create Bar Charts: Using the barplot function from base R, we can create a very simple and straightforward bar chart without too many frills and embellishments. Let’s start with the Facility variable. As the sole parenthetical argument in the barplot function, simply, enter the table(demo$Facility) code that we wrote in the previous section.
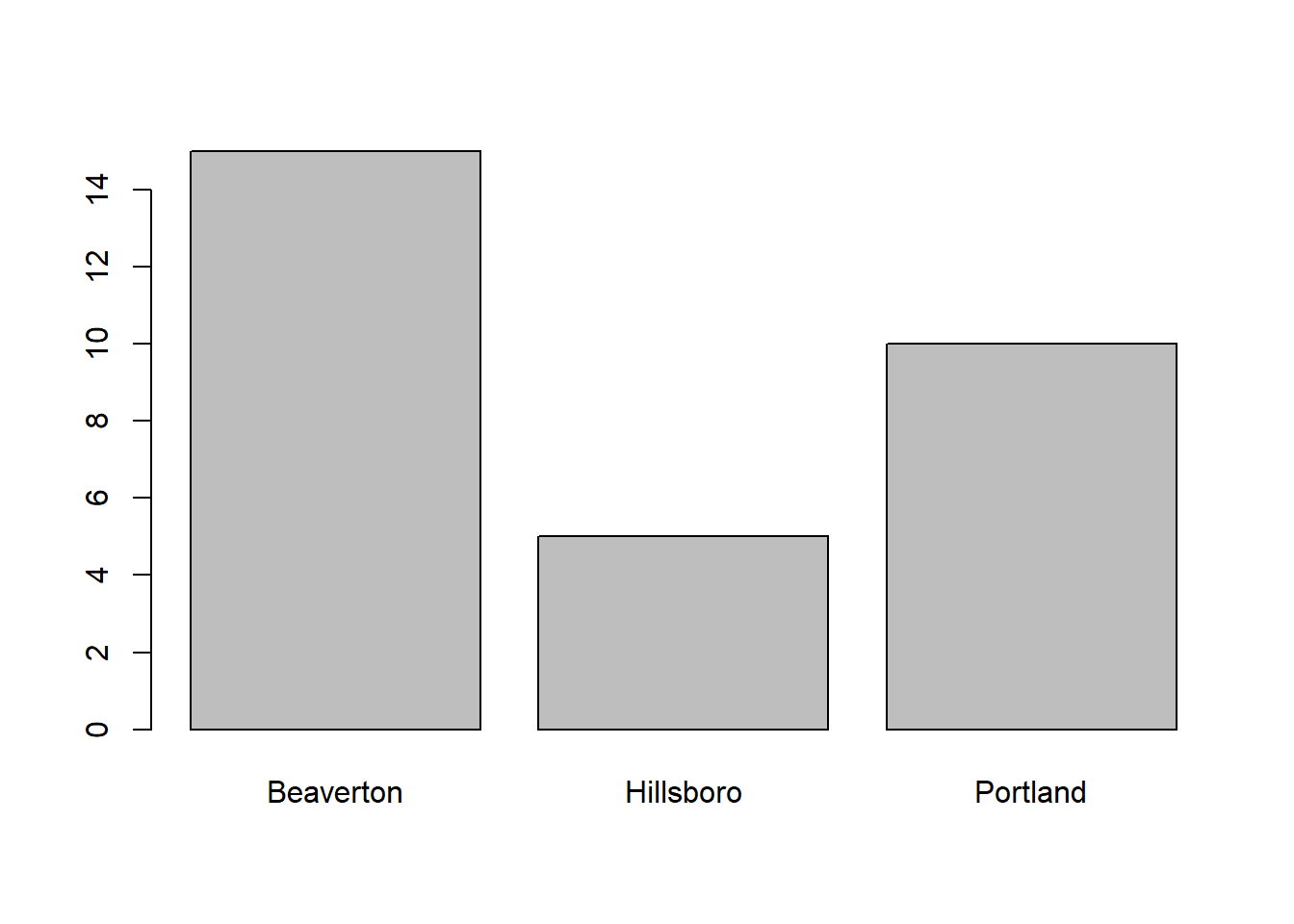
As you can see, a very simple (and not super aesthetically pleasing) bar chart appears in our Plots window. When exploring data on our own, it is often fine to just complete a simple bar chart like this one, as opposed to fine-tuning the aesthetics (e.g., size, color, font) of the plot. If you want, you can export this plot as a PDF or PNG image file, or you can copy it and paste it in another document. To do so, just click on the Export button in the Plots window, which should appear in the lower right of your RStudio interface.
If you’re feeling adventurous and would like to learn how to fine-tune the bar chart, feel free to continue on with this tutorial. Additional attention paid to aesthetics might be worthwhile if you plan to present the plot to others in a formal presentation or report.
Using the barplot code we wrote above, we can add a second argument in which we apply ylim= followed by a vector (using the c function) of the lower and upper limits for the y-axis. In this example, I set the lower and upper y-axis limits to 0 and 20.
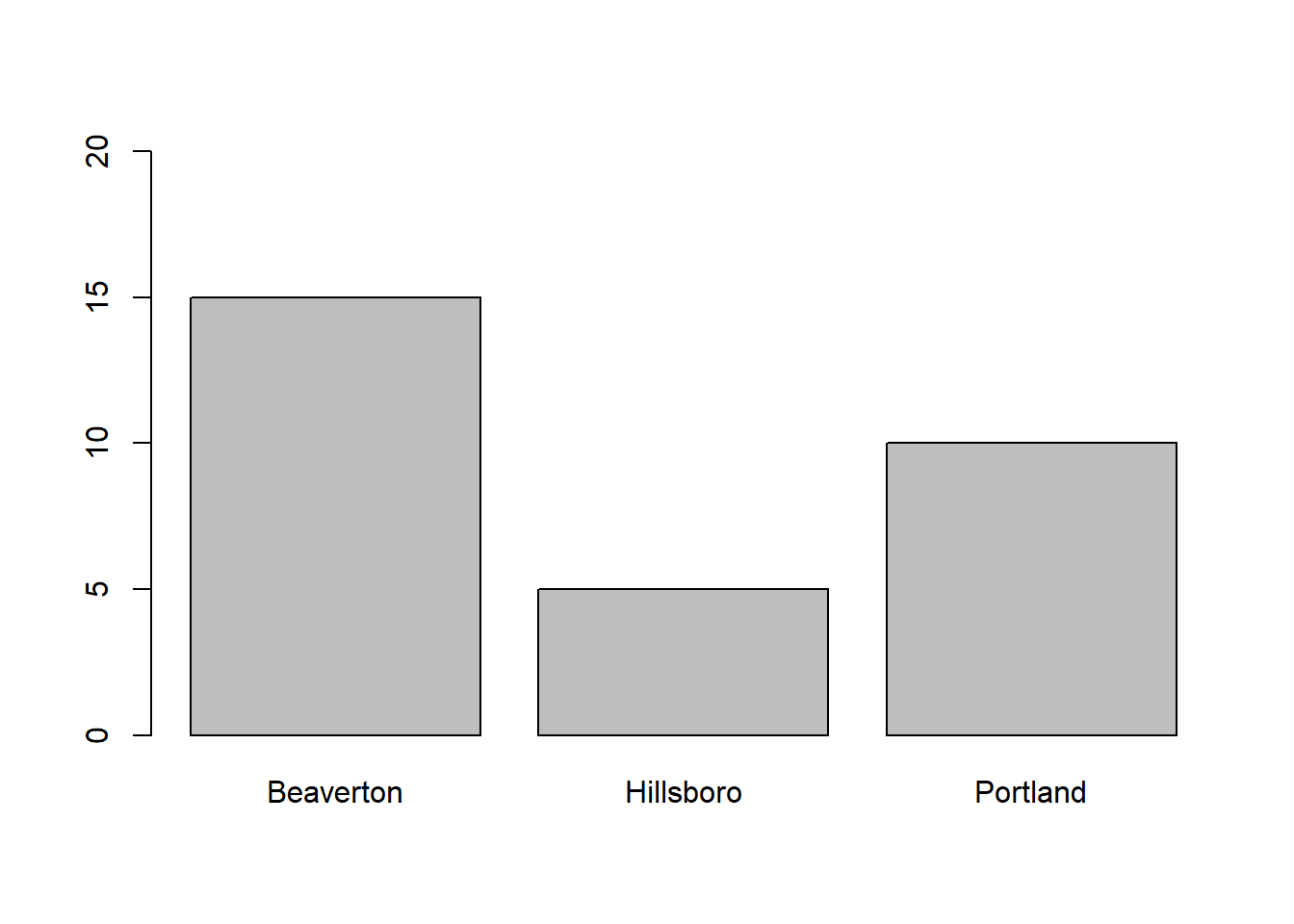
Building on the previous code, we add additional arguments in which we provide more meaningful labels for the x- and y-axes. To do so, we use the xlab argument for the x-axis label and the ylab argument for the y-axis label. Just make sure to put quotation marks (" ") around whatever text you come up with for your axis labels.
# Create a bar chart based on Facility counts
barplot(table(demo$Facility),
ylim=c(0,20),
xlab="Facility",
ylab="Counts")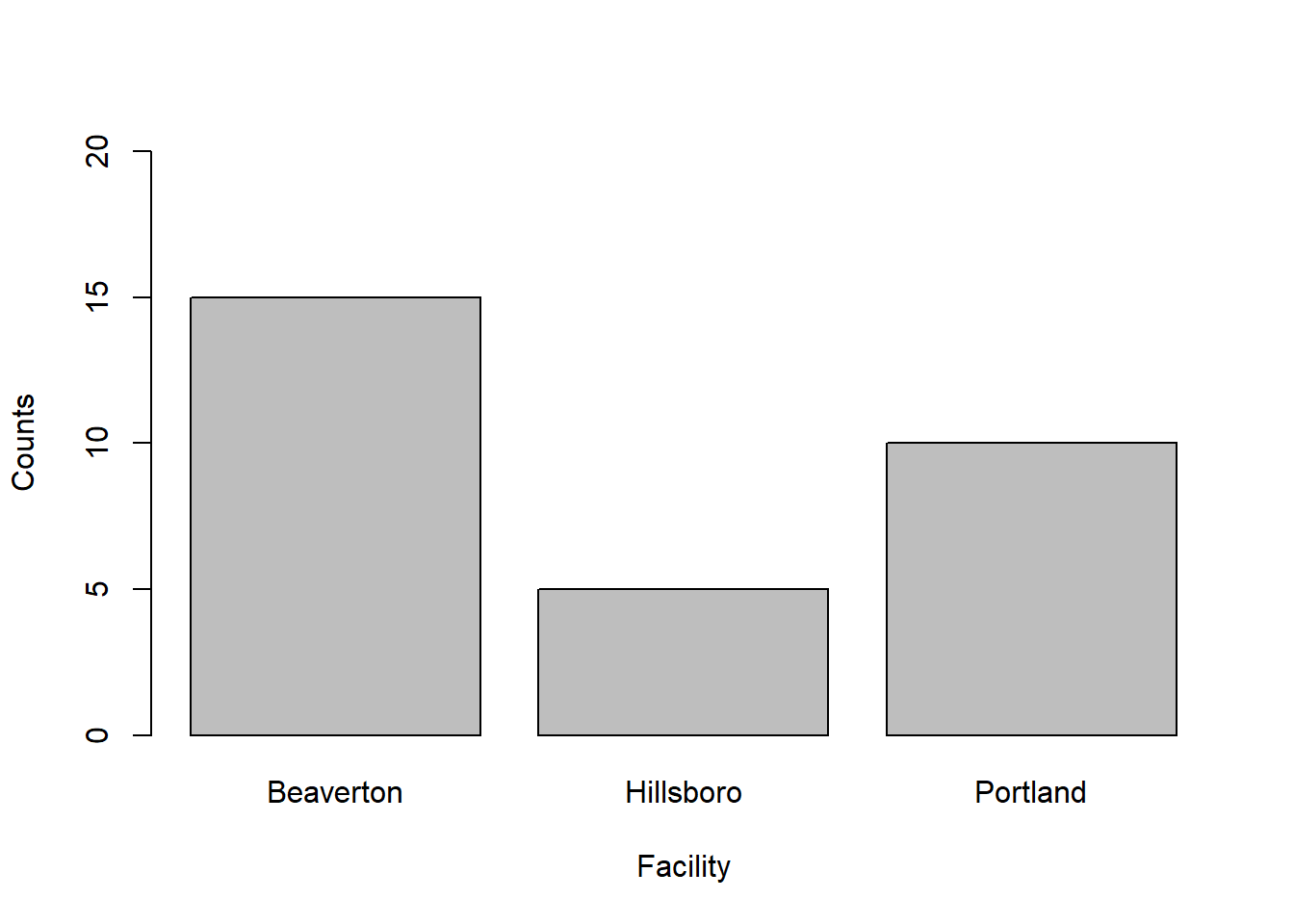
We can change the colors of the bars by adding the col (color) argument. There are many, many different colors that can be used in R, and one of my favorites is “dodgerblue”.
# Create a bar chart based on Facility counts
barplot(table(demo$Facility),
ylim=c(0,20),
xlab="Facility",
ylab="Counts",
col="dodgerblue")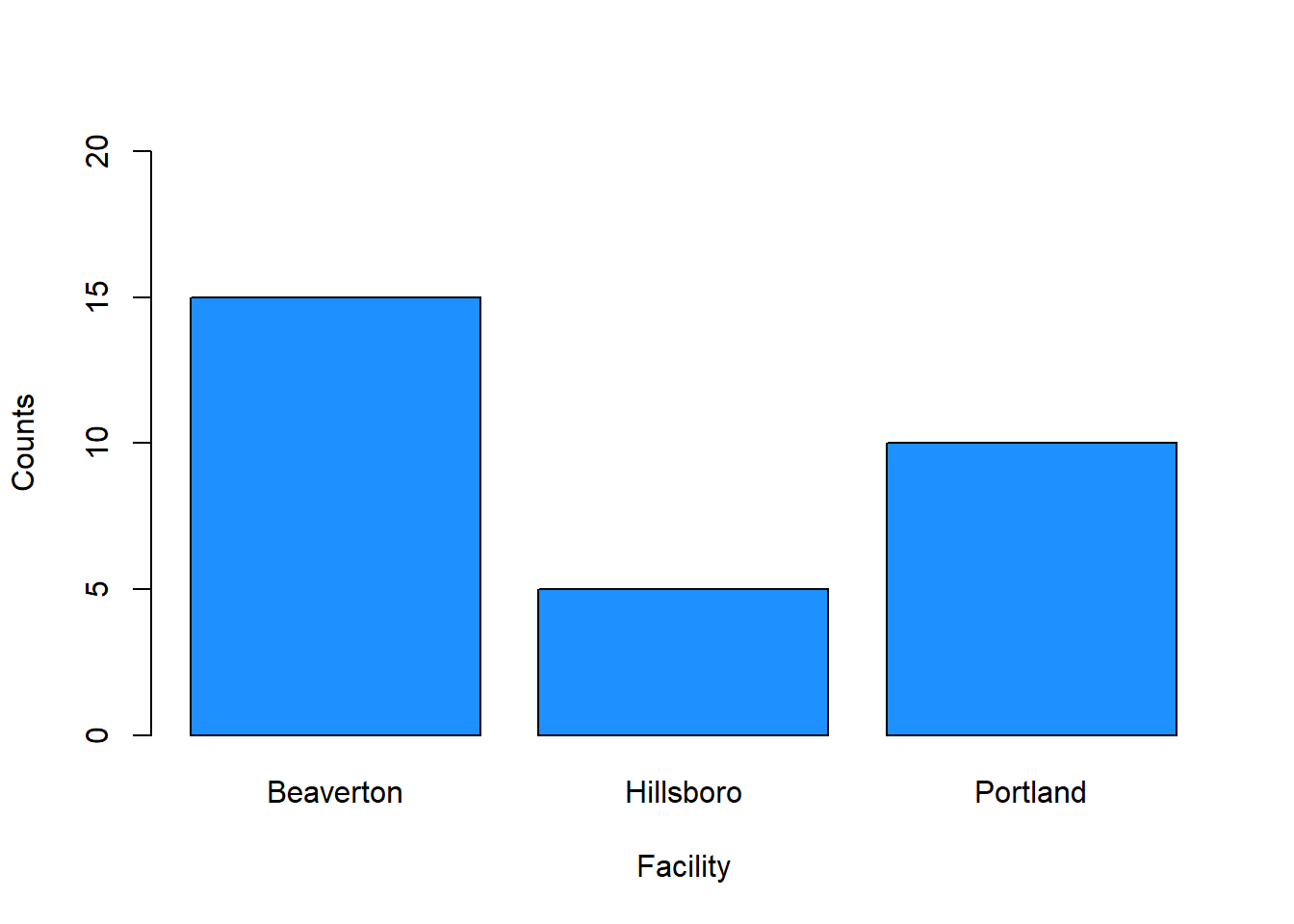
If you’d like to explore additional colors, check out this website: https://www.r-graph-gallery.com/colors.html. Or, you can run the colors() function (without any arguments), and you’ll get a (huge) list of the color options.
## [1] "white" "aliceblue" "antiquewhite" "antiquewhite1" "antiquewhite2"
## [6] "antiquewhite3" "antiquewhite4" "aquamarine" "aquamarine1" "aquamarine2"
## [11] "aquamarine3" "aquamarine4" "azure" "azure1" "azure2"
## [16] "azure3" "azure4" "beige" "bisque" "bisque1"
## [21] "bisque2" "bisque3" "bisque4" "black" "blanchedalmond"
## [26] "blue" "blue1" "blue2" "blue3" "blue4"
## [31] "blueviolet" "brown" "brown1" "brown2" "brown3"
## [36] "brown4" "burlywood" "burlywood1" "burlywood2" "burlywood3"
## [41] "burlywood4" "cadetblue" "cadetblue1" "cadetblue2" "cadetblue3"
## [46] "cadetblue4" "chartreuse" "chartreuse1" "chartreuse2" "chartreuse3"
## [51] "chartreuse4" "chocolate" "chocolate1" "chocolate2" "chocolate3"
## [56] "chocolate4" "coral" "coral1" "coral2" "coral3"
## [61] "coral4" "cornflowerblue" "cornsilk" "cornsilk1" "cornsilk2"
## [66] "cornsilk3" "cornsilk4" "cyan" "cyan1" "cyan2"
## [71] "cyan3" "cyan4" "darkblue" "darkcyan" "darkgoldenrod"
## [76] "darkgoldenrod1" "darkgoldenrod2" "darkgoldenrod3" "darkgoldenrod4" "darkgray"
## [81] "darkgreen" "darkgrey" "darkkhaki" "darkmagenta" "darkolivegreen"
## [86] "darkolivegreen1" "darkolivegreen2" "darkolivegreen3" "darkolivegreen4" "darkorange"
## [91] "darkorange1" "darkorange2" "darkorange3" "darkorange4" "darkorchid"
## [96] "darkorchid1" "darkorchid2" "darkorchid3" "darkorchid4" "darkred"
## [101] "darksalmon" "darkseagreen" "darkseagreen1" "darkseagreen2" "darkseagreen3"
## [106] "darkseagreen4" "darkslateblue" "darkslategray" "darkslategray1" "darkslategray2"
## [111] "darkslategray3" "darkslategray4" "darkslategrey" "darkturquoise" "darkviolet"
## [116] "deeppink" "deeppink1" "deeppink2" "deeppink3" "deeppink4"
## [121] "deepskyblue" "deepskyblue1" "deepskyblue2" "deepskyblue3" "deepskyblue4"
## [126] "dimgray" "dimgrey" "dodgerblue" "dodgerblue1" "dodgerblue2"
## [131] "dodgerblue3" "dodgerblue4" "firebrick" "firebrick1" "firebrick2"
## [136] "firebrick3" "firebrick4" "floralwhite" "forestgreen" "gainsboro"
## [141] "ghostwhite" "gold" "gold1" "gold2" "gold3"
## [146] "gold4" "goldenrod" "goldenrod1" "goldenrod2" "goldenrod3"
## [151] "goldenrod4" "gray" "gray0" "gray1" "gray2"
## [156] "gray3" "gray4" "gray5" "gray6" "gray7"
## [161] "gray8" "gray9" "gray10" "gray11" "gray12"
## [166] "gray13" "gray14" "gray15" "gray16" "gray17"
## [171] "gray18" "gray19" "gray20" "gray21" "gray22"
## [176] "gray23" "gray24" "gray25" "gray26" "gray27"
## [181] "gray28" "gray29" "gray30" "gray31" "gray32"
## [186] "gray33" "gray34" "gray35" "gray36" "gray37"
## [191] "gray38" "gray39" "gray40" "gray41" "gray42"
## [196] "gray43" "gray44" "gray45" "gray46" "gray47"
## [201] "gray48" "gray49" "gray50" "gray51" "gray52"
## [206] "gray53" "gray54" "gray55" "gray56" "gray57"
## [211] "gray58" "gray59" "gray60" "gray61" "gray62"
## [216] "gray63" "gray64" "gray65" "gray66" "gray67"
## [221] "gray68" "gray69" "gray70" "gray71" "gray72"
## [226] "gray73" "gray74" "gray75" "gray76" "gray77"
## [231] "gray78" "gray79" "gray80" "gray81" "gray82"
## [236] "gray83" "gray84" "gray85" "gray86" "gray87"
## [241] "gray88" "gray89" "gray90" "gray91" "gray92"
## [246] "gray93" "gray94" "gray95" "gray96" "gray97"
## [251] "gray98" "gray99" "gray100" "green" "green1"
## [256] "green2" "green3" "green4" "greenyellow" "grey"
## [261] "grey0" "grey1" "grey2" "grey3" "grey4"
## [266] "grey5" "grey6" "grey7" "grey8" "grey9"
## [271] "grey10" "grey11" "grey12" "grey13" "grey14"
## [276] "grey15" "grey16" "grey17" "grey18" "grey19"
## [281] "grey20" "grey21" "grey22" "grey23" "grey24"
## [286] "grey25" "grey26" "grey27" "grey28" "grey29"
## [291] "grey30" "grey31" "grey32" "grey33" "grey34"
## [296] "grey35" "grey36" "grey37" "grey38" "grey39"
## [301] "grey40" "grey41" "grey42" "grey43" "grey44"
## [306] "grey45" "grey46" "grey47" "grey48" "grey49"
## [311] "grey50" "grey51" "grey52" "grey53" "grey54"
## [316] "grey55" "grey56" "grey57" "grey58" "grey59"
## [321] "grey60" "grey61" "grey62" "grey63" "grey64"
## [326] "grey65" "grey66" "grey67" "grey68" "grey69"
## [331] "grey70" "grey71" "grey72" "grey73" "grey74"
## [336] "grey75" "grey76" "grey77" "grey78" "grey79"
## [341] "grey80" "grey81" "grey82" "grey83" "grey84"
## [346] "grey85" "grey86" "grey87" "grey88" "grey89"
## [351] "grey90" "grey91" "grey92" "grey93" "grey94"
## [356] "grey95" "grey96" "grey97" "grey98" "grey99"
## [361] "grey100" "honeydew" "honeydew1" "honeydew2" "honeydew3"
## [366] "honeydew4" "hotpink" "hotpink1" "hotpink2" "hotpink3"
## [371] "hotpink4" "indianred" "indianred1" "indianred2" "indianred3"
## [376] "indianred4" "ivory" "ivory1" "ivory2" "ivory3"
## [381] "ivory4" "khaki" "khaki1" "khaki2" "khaki3"
## [386] "khaki4" "lavender" "lavenderblush" "lavenderblush1" "lavenderblush2"
## [391] "lavenderblush3" "lavenderblush4" "lawngreen" "lemonchiffon" "lemonchiffon1"
## [396] "lemonchiffon2" "lemonchiffon3" "lemonchiffon4" "lightblue" "lightblue1"
## [401] "lightblue2" "lightblue3" "lightblue4" "lightcoral" "lightcyan"
## [406] "lightcyan1" "lightcyan2" "lightcyan3" "lightcyan4" "lightgoldenrod"
## [411] "lightgoldenrod1" "lightgoldenrod2" "lightgoldenrod3" "lightgoldenrod4" "lightgoldenrodyellow"
## [416] "lightgray" "lightgreen" "lightgrey" "lightpink" "lightpink1"
## [421] "lightpink2" "lightpink3" "lightpink4" "lightsalmon" "lightsalmon1"
## [426] "lightsalmon2" "lightsalmon3" "lightsalmon4" "lightseagreen" "lightskyblue"
## [431] "lightskyblue1" "lightskyblue2" "lightskyblue3" "lightskyblue4" "lightslateblue"
## [436] "lightslategray" "lightslategrey" "lightsteelblue" "lightsteelblue1" "lightsteelblue2"
## [441] "lightsteelblue3" "lightsteelblue4" "lightyellow" "lightyellow1" "lightyellow2"
## [446] "lightyellow3" "lightyellow4" "limegreen" "linen" "magenta"
## [451] "magenta1" "magenta2" "magenta3" "magenta4" "maroon"
## [456] "maroon1" "maroon2" "maroon3" "maroon4" "mediumaquamarine"
## [461] "mediumblue" "mediumorchid" "mediumorchid1" "mediumorchid2" "mediumorchid3"
## [466] "mediumorchid4" "mediumpurple" "mediumpurple1" "mediumpurple2" "mediumpurple3"
## [471] "mediumpurple4" "mediumseagreen" "mediumslateblue" "mediumspringgreen" "mediumturquoise"
## [476] "mediumvioletred" "midnightblue" "mintcream" "mistyrose" "mistyrose1"
## [481] "mistyrose2" "mistyrose3" "mistyrose4" "moccasin" "navajowhite"
## [486] "navajowhite1" "navajowhite2" "navajowhite3" "navajowhite4" "navy"
## [491] "navyblue" "oldlace" "olivedrab" "olivedrab1" "olivedrab2"
## [496] "olivedrab3" "olivedrab4" "orange" "orange1" "orange2"
## [501] "orange3" "orange4" "orangered" "orangered1" "orangered2"
## [506] "orangered3" "orangered4" "orchid" "orchid1" "orchid2"
## [511] "orchid3" "orchid4" "palegoldenrod" "palegreen" "palegreen1"
## [516] "palegreen2" "palegreen3" "palegreen4" "paleturquoise" "paleturquoise1"
## [521] "paleturquoise2" "paleturquoise3" "paleturquoise4" "palevioletred" "palevioletred1"
## [526] "palevioletred2" "palevioletred3" "palevioletred4" "papayawhip" "peachpuff"
## [531] "peachpuff1" "peachpuff2" "peachpuff3" "peachpuff4" "peru"
## [536] "pink" "pink1" "pink2" "pink3" "pink4"
## [541] "plum" "plum1" "plum2" "plum3" "plum4"
## [546] "powderblue" "purple" "purple1" "purple2" "purple3"
## [551] "purple4" "red" "red1" "red2" "red3"
## [556] "red4" "rosybrown" "rosybrown1" "rosybrown2" "rosybrown3"
## [561] "rosybrown4" "royalblue" "royalblue1" "royalblue2" "royalblue3"
## [566] "royalblue4" "saddlebrown" "salmon" "salmon1" "salmon2"
## [571] "salmon3" "salmon4" "sandybrown" "seagreen" "seagreen1"
## [576] "seagreen2" "seagreen3" "seagreen4" "seashell" "seashell1"
## [581] "seashell2" "seashell3" "seashell4" "sienna" "sienna1"
## [586] "sienna2" "sienna3" "sienna4" "skyblue" "skyblue1"
## [591] "skyblue2" "skyblue3" "skyblue4" "slateblue" "slateblue1"
## [596] "slateblue2" "slateblue3" "slateblue4" "slategray" "slategray1"
## [601] "slategray2" "slategray3" "slategray4" "slategrey" "snow"
## [606] "snow1" "snow2" "snow3" "snow4" "springgreen"
## [611] "springgreen1" "springgreen2" "springgreen3" "springgreen4" "steelblue"
## [616] "steelblue1" "steelblue2" "steelblue3" "steelblue4" "tan"
## [621] "tan1" "tan2" "tan3" "tan4" "thistle"
## [626] "thistle1" "thistle2" "thistle3" "thistle4" "tomato"
## [631] "tomato1" "tomato2" "tomato3" "tomato4" "turquoise"
## [636] "turquoise1" "turquoise2" "turquoise3" "turquoise4" "violet"
## [641] "violetred" "violetred1" "violetred2" "violetred3" "violetred4"
## [646] "wheat" "wheat1" "wheat2" "wheat3" "wheat4"
## [651] "whitesmoke" "yellow" "yellow1" "yellow2" "yellow3"
## [656] "yellow4" "yellowgreen"Finally, the barplot function does not provide a horizontal line where the y-axis is equal to 0. If you’d like to add such a line, simply follow up your barplot function with the abline function, and as the sole argument, type h=0.
# Create a bar chart based on Facility counts
barplot(table(demo$Facility),
ylim=c(0,20),
xlab="Facility",
ylab="Counts",
col="dodgerblue")
abline(h=0)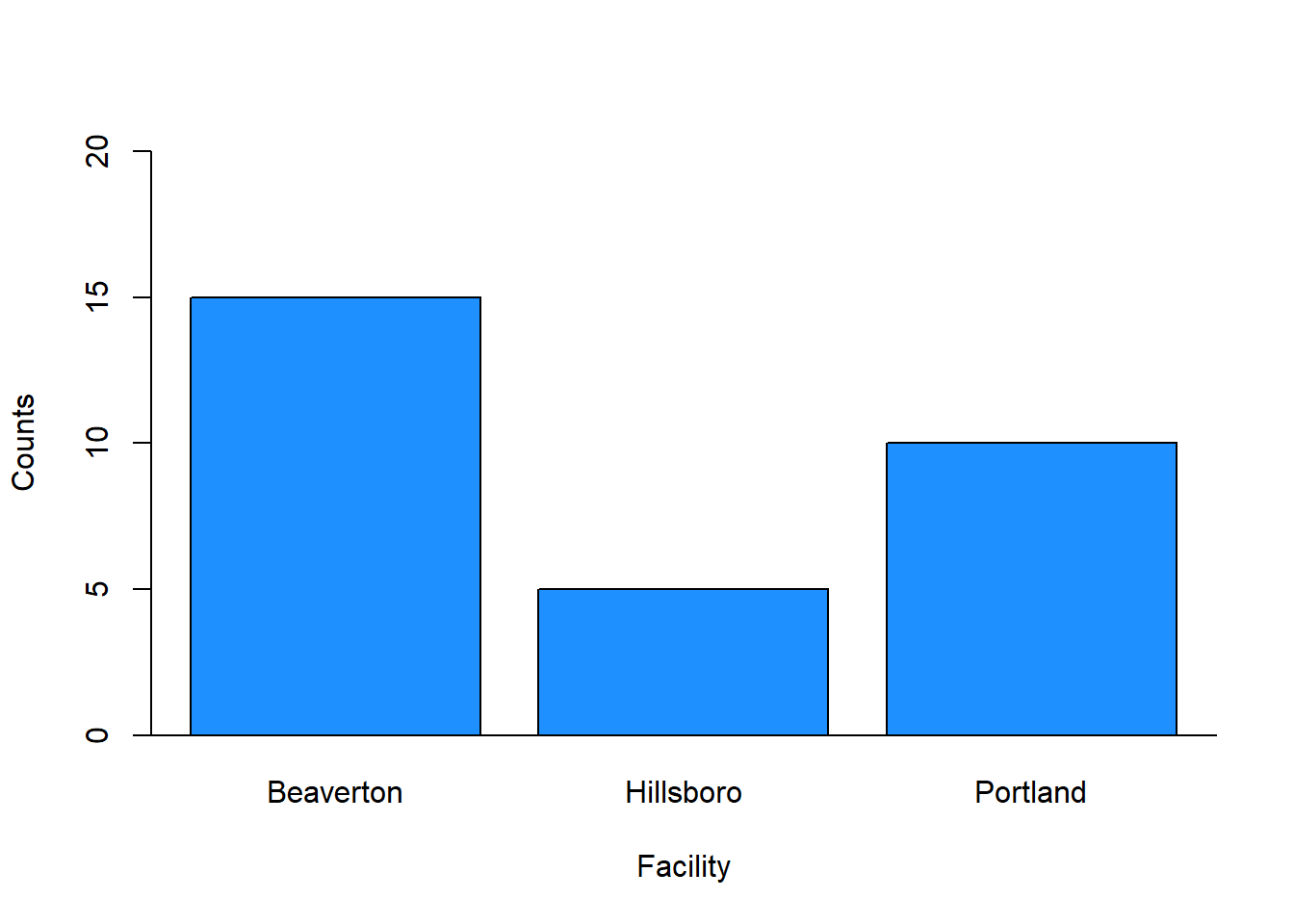
And finally, here’s a quick example of how you might visualize the Education variable using the barplot function.
# Create a bar chart for Education variable
barplot(table(demo$Education),
ylim=c(0,20),
xlab="Education Level",
ylab="Counts",
col="orange")
abline(h=0)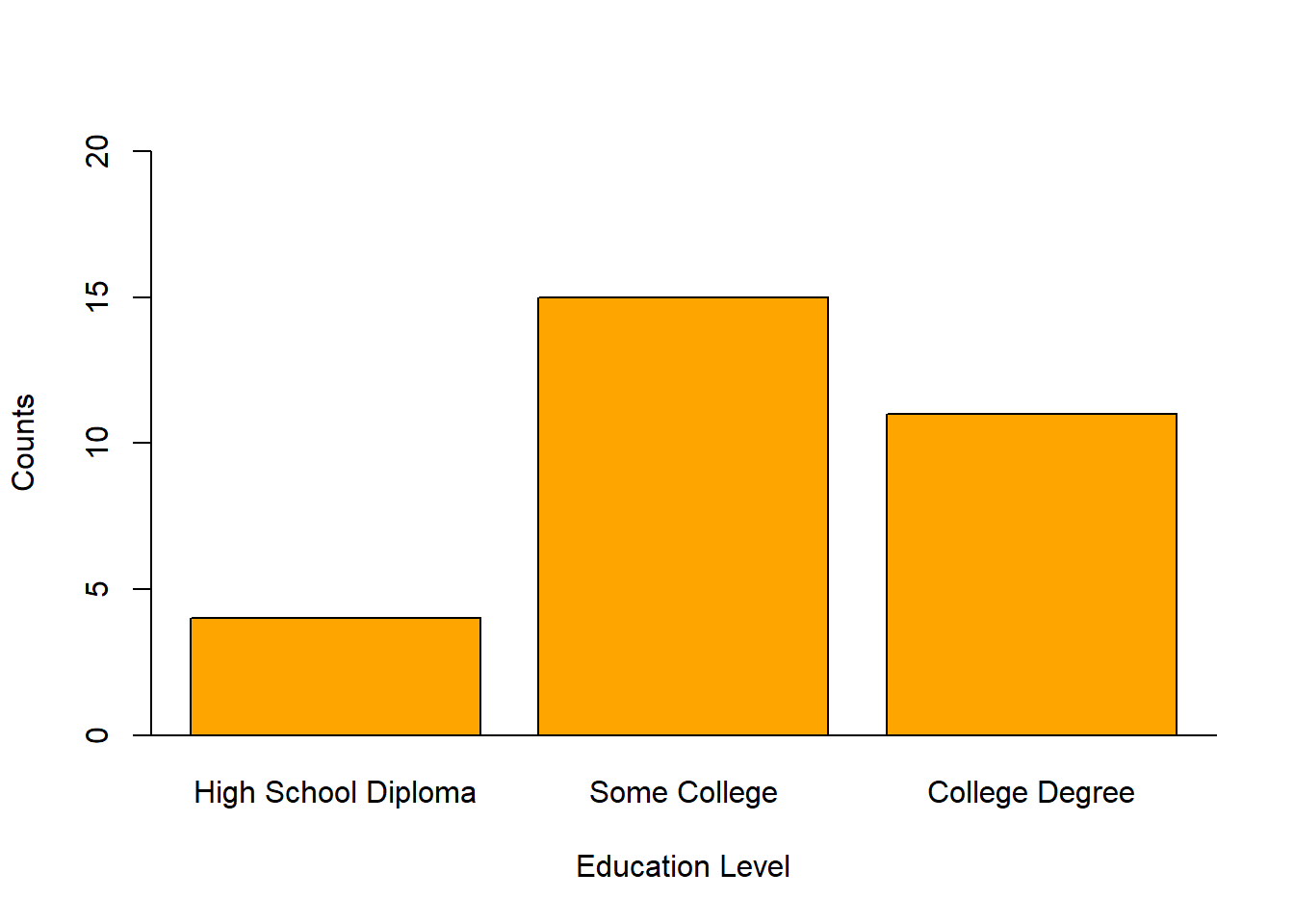
Create Pie Charts: Using the pie function from base R, we can create a very simple and straightforward bar chart without too many frills and embellishments. Let’s start with the Education variable. As the sole parenthetical argument in the barplot function, simply, enter the table(demo$Education) code that we wrote in the section called Compute Counts & Frequencies.
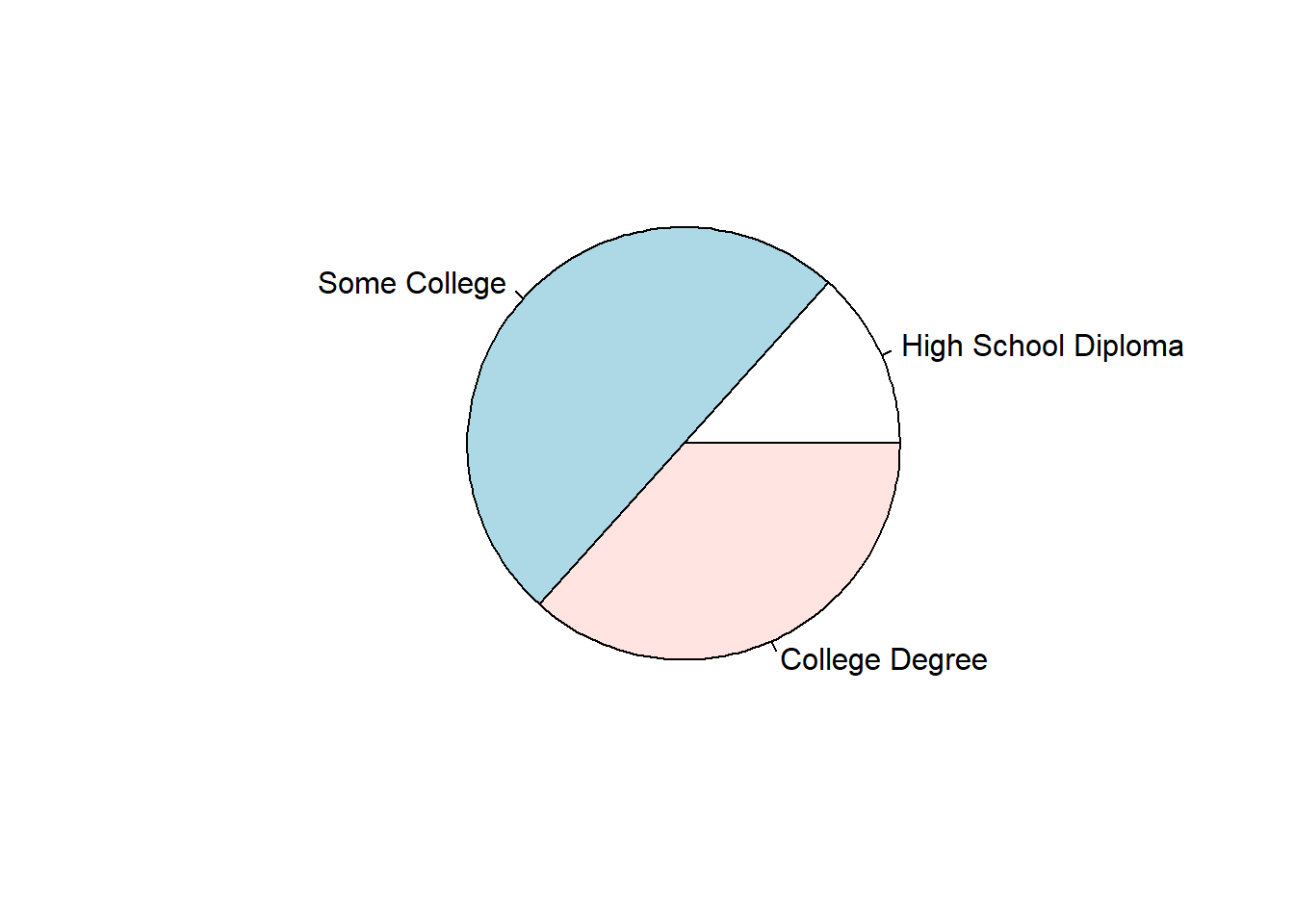
A very simple and generic pie chart appears in our Plots window. When exploring data on our own, it is often fine to just complete a simple pie chart like this one, as opposed to fine-tuning the aesthetics (e.g., size, color, font) of the plot. If you want, you can export this plot as a PDF or PNG image file, or you can copy it and paste it in another document. To do so, just click on the Export button in the Plots window, which should appear in the lower right of your RStudio interface.
If you’re feeling adventurous and would like to learn how to adjust the colors pie chart, feel free to continue on with this tutorial.
Using the pie code we wrote above, let’s add the col= argument followed by the c (combine) function containing a vector of colors – one color for each slice of the pie. Here, I chose the primar colors of red, yellow, and blue.
# Create a bar chart based on Education counts
pie(table(demo$Education),
col=c("red", "yellow", "blue"))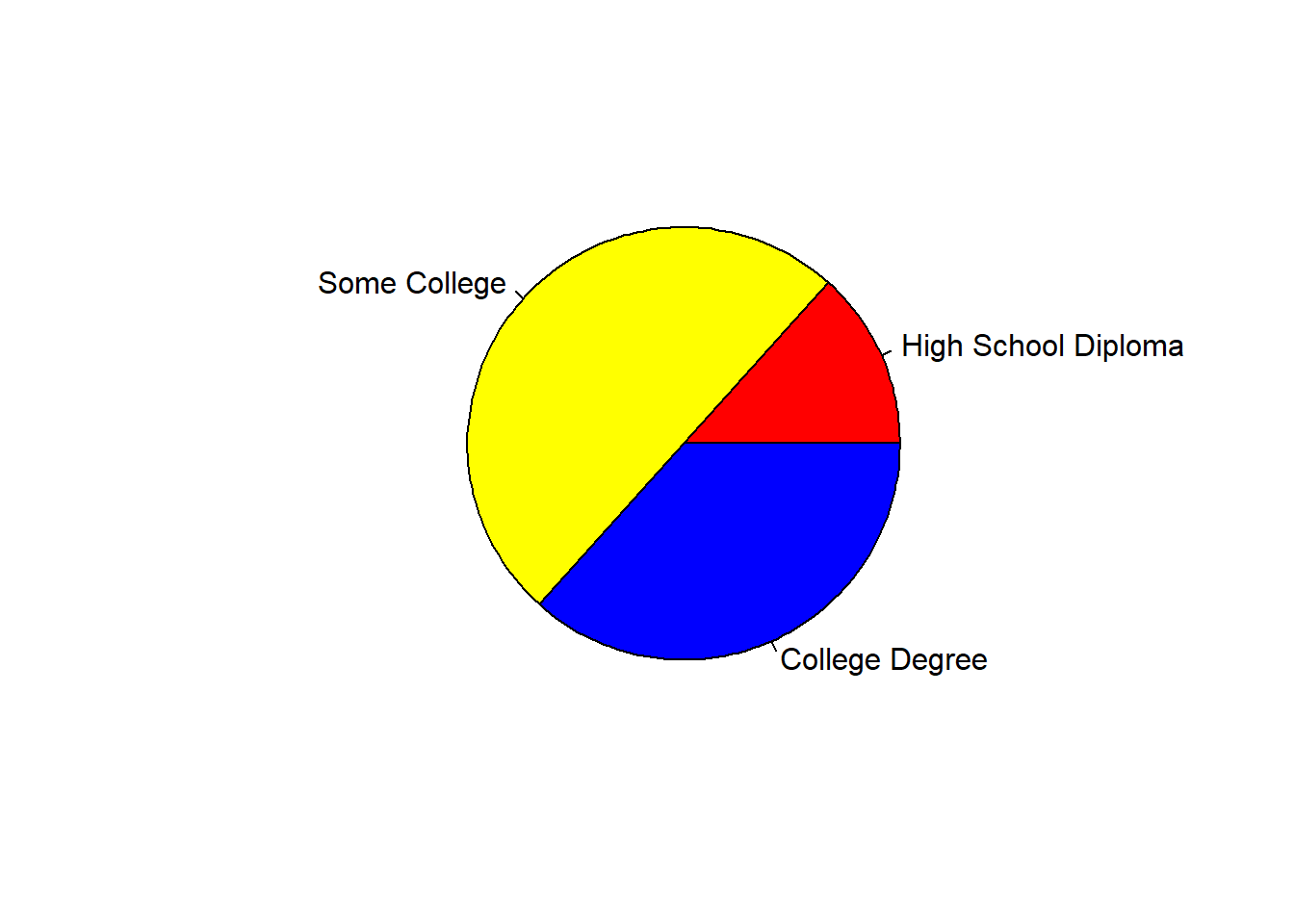
If you’d like to explore additional colors, check out this website: https://www.r-graph-gallery.com/colors.html. Or, you can run the colors() function (without any arguments), and you’ll get a (huge) list of the color options.
## [1] "white" "aliceblue" "antiquewhite" "antiquewhite1" "antiquewhite2"
## [6] "antiquewhite3" "antiquewhite4" "aquamarine" "aquamarine1" "aquamarine2"
## [11] "aquamarine3" "aquamarine4" "azure" "azure1" "azure2"
## [16] "azure3" "azure4" "beige" "bisque" "bisque1"
## [21] "bisque2" "bisque3" "bisque4" "black" "blanchedalmond"
## [26] "blue" "blue1" "blue2" "blue3" "blue4"
## [31] "blueviolet" "brown" "brown1" "brown2" "brown3"
## [36] "brown4" "burlywood" "burlywood1" "burlywood2" "burlywood3"
## [41] "burlywood4" "cadetblue" "cadetblue1" "cadetblue2" "cadetblue3"
## [46] "cadetblue4" "chartreuse" "chartreuse1" "chartreuse2" "chartreuse3"
## [51] "chartreuse4" "chocolate" "chocolate1" "chocolate2" "chocolate3"
## [56] "chocolate4" "coral" "coral1" "coral2" "coral3"
## [61] "coral4" "cornflowerblue" "cornsilk" "cornsilk1" "cornsilk2"
## [66] "cornsilk3" "cornsilk4" "cyan" "cyan1" "cyan2"
## [71] "cyan3" "cyan4" "darkblue" "darkcyan" "darkgoldenrod"
## [76] "darkgoldenrod1" "darkgoldenrod2" "darkgoldenrod3" "darkgoldenrod4" "darkgray"
## [81] "darkgreen" "darkgrey" "darkkhaki" "darkmagenta" "darkolivegreen"
## [86] "darkolivegreen1" "darkolivegreen2" "darkolivegreen3" "darkolivegreen4" "darkorange"
## [91] "darkorange1" "darkorange2" "darkorange3" "darkorange4" "darkorchid"
## [96] "darkorchid1" "darkorchid2" "darkorchid3" "darkorchid4" "darkred"
## [101] "darksalmon" "darkseagreen" "darkseagreen1" "darkseagreen2" "darkseagreen3"
## [106] "darkseagreen4" "darkslateblue" "darkslategray" "darkslategray1" "darkslategray2"
## [111] "darkslategray3" "darkslategray4" "darkslategrey" "darkturquoise" "darkviolet"
## [116] "deeppink" "deeppink1" "deeppink2" "deeppink3" "deeppink4"
## [121] "deepskyblue" "deepskyblue1" "deepskyblue2" "deepskyblue3" "deepskyblue4"
## [126] "dimgray" "dimgrey" "dodgerblue" "dodgerblue1" "dodgerblue2"
## [131] "dodgerblue3" "dodgerblue4" "firebrick" "firebrick1" "firebrick2"
## [136] "firebrick3" "firebrick4" "floralwhite" "forestgreen" "gainsboro"
## [141] "ghostwhite" "gold" "gold1" "gold2" "gold3"
## [146] "gold4" "goldenrod" "goldenrod1" "goldenrod2" "goldenrod3"
## [151] "goldenrod4" "gray" "gray0" "gray1" "gray2"
## [156] "gray3" "gray4" "gray5" "gray6" "gray7"
## [161] "gray8" "gray9" "gray10" "gray11" "gray12"
## [166] "gray13" "gray14" "gray15" "gray16" "gray17"
## [171] "gray18" "gray19" "gray20" "gray21" "gray22"
## [176] "gray23" "gray24" "gray25" "gray26" "gray27"
## [181] "gray28" "gray29" "gray30" "gray31" "gray32"
## [186] "gray33" "gray34" "gray35" "gray36" "gray37"
## [191] "gray38" "gray39" "gray40" "gray41" "gray42"
## [196] "gray43" "gray44" "gray45" "gray46" "gray47"
## [201] "gray48" "gray49" "gray50" "gray51" "gray52"
## [206] "gray53" "gray54" "gray55" "gray56" "gray57"
## [211] "gray58" "gray59" "gray60" "gray61" "gray62"
## [216] "gray63" "gray64" "gray65" "gray66" "gray67"
## [221] "gray68" "gray69" "gray70" "gray71" "gray72"
## [226] "gray73" "gray74" "gray75" "gray76" "gray77"
## [231] "gray78" "gray79" "gray80" "gray81" "gray82"
## [236] "gray83" "gray84" "gray85" "gray86" "gray87"
## [241] "gray88" "gray89" "gray90" "gray91" "gray92"
## [246] "gray93" "gray94" "gray95" "gray96" "gray97"
## [251] "gray98" "gray99" "gray100" "green" "green1"
## [256] "green2" "green3" "green4" "greenyellow" "grey"
## [261] "grey0" "grey1" "grey2" "grey3" "grey4"
## [266] "grey5" "grey6" "grey7" "grey8" "grey9"
## [271] "grey10" "grey11" "grey12" "grey13" "grey14"
## [276] "grey15" "grey16" "grey17" "grey18" "grey19"
## [281] "grey20" "grey21" "grey22" "grey23" "grey24"
## [286] "grey25" "grey26" "grey27" "grey28" "grey29"
## [291] "grey30" "grey31" "grey32" "grey33" "grey34"
## [296] "grey35" "grey36" "grey37" "grey38" "grey39"
## [301] "grey40" "grey41" "grey42" "grey43" "grey44"
## [306] "grey45" "grey46" "grey47" "grey48" "grey49"
## [311] "grey50" "grey51" "grey52" "grey53" "grey54"
## [316] "grey55" "grey56" "grey57" "grey58" "grey59"
## [321] "grey60" "grey61" "grey62" "grey63" "grey64"
## [326] "grey65" "grey66" "grey67" "grey68" "grey69"
## [331] "grey70" "grey71" "grey72" "grey73" "grey74"
## [336] "grey75" "grey76" "grey77" "grey78" "grey79"
## [341] "grey80" "grey81" "grey82" "grey83" "grey84"
## [346] "grey85" "grey86" "grey87" "grey88" "grey89"
## [351] "grey90" "grey91" "grey92" "grey93" "grey94"
## [356] "grey95" "grey96" "grey97" "grey98" "grey99"
## [361] "grey100" "honeydew" "honeydew1" "honeydew2" "honeydew3"
## [366] "honeydew4" "hotpink" "hotpink1" "hotpink2" "hotpink3"
## [371] "hotpink4" "indianred" "indianred1" "indianred2" "indianred3"
## [376] "indianred4" "ivory" "ivory1" "ivory2" "ivory3"
## [381] "ivory4" "khaki" "khaki1" "khaki2" "khaki3"
## [386] "khaki4" "lavender" "lavenderblush" "lavenderblush1" "lavenderblush2"
## [391] "lavenderblush3" "lavenderblush4" "lawngreen" "lemonchiffon" "lemonchiffon1"
## [396] "lemonchiffon2" "lemonchiffon3" "lemonchiffon4" "lightblue" "lightblue1"
## [401] "lightblue2" "lightblue3" "lightblue4" "lightcoral" "lightcyan"
## [406] "lightcyan1" "lightcyan2" "lightcyan3" "lightcyan4" "lightgoldenrod"
## [411] "lightgoldenrod1" "lightgoldenrod2" "lightgoldenrod3" "lightgoldenrod4" "lightgoldenrodyellow"
## [416] "lightgray" "lightgreen" "lightgrey" "lightpink" "lightpink1"
## [421] "lightpink2" "lightpink3" "lightpink4" "lightsalmon" "lightsalmon1"
## [426] "lightsalmon2" "lightsalmon3" "lightsalmon4" "lightseagreen" "lightskyblue"
## [431] "lightskyblue1" "lightskyblue2" "lightskyblue3" "lightskyblue4" "lightslateblue"
## [436] "lightslategray" "lightslategrey" "lightsteelblue" "lightsteelblue1" "lightsteelblue2"
## [441] "lightsteelblue3" "lightsteelblue4" "lightyellow" "lightyellow1" "lightyellow2"
## [446] "lightyellow3" "lightyellow4" "limegreen" "linen" "magenta"
## [451] "magenta1" "magenta2" "magenta3" "magenta4" "maroon"
## [456] "maroon1" "maroon2" "maroon3" "maroon4" "mediumaquamarine"
## [461] "mediumblue" "mediumorchid" "mediumorchid1" "mediumorchid2" "mediumorchid3"
## [466] "mediumorchid4" "mediumpurple" "mediumpurple1" "mediumpurple2" "mediumpurple3"
## [471] "mediumpurple4" "mediumseagreen" "mediumslateblue" "mediumspringgreen" "mediumturquoise"
## [476] "mediumvioletred" "midnightblue" "mintcream" "mistyrose" "mistyrose1"
## [481] "mistyrose2" "mistyrose3" "mistyrose4" "moccasin" "navajowhite"
## [486] "navajowhite1" "navajowhite2" "navajowhite3" "navajowhite4" "navy"
## [491] "navyblue" "oldlace" "olivedrab" "olivedrab1" "olivedrab2"
## [496] "olivedrab3" "olivedrab4" "orange" "orange1" "orange2"
## [501] "orange3" "orange4" "orangered" "orangered1" "orangered2"
## [506] "orangered3" "orangered4" "orchid" "orchid1" "orchid2"
## [511] "orchid3" "orchid4" "palegoldenrod" "palegreen" "palegreen1"
## [516] "palegreen2" "palegreen3" "palegreen4" "paleturquoise" "paleturquoise1"
## [521] "paleturquoise2" "paleturquoise3" "paleturquoise4" "palevioletred" "palevioletred1"
## [526] "palevioletred2" "palevioletred3" "palevioletred4" "papayawhip" "peachpuff"
## [531] "peachpuff1" "peachpuff2" "peachpuff3" "peachpuff4" "peru"
## [536] "pink" "pink1" "pink2" "pink3" "pink4"
## [541] "plum" "plum1" "plum2" "plum3" "plum4"
## [546] "powderblue" "purple" "purple1" "purple2" "purple3"
## [551] "purple4" "red" "red1" "red2" "red3"
## [556] "red4" "rosybrown" "rosybrown1" "rosybrown2" "rosybrown3"
## [561] "rosybrown4" "royalblue" "royalblue1" "royalblue2" "royalblue3"
## [566] "royalblue4" "saddlebrown" "salmon" "salmon1" "salmon2"
## [571] "salmon3" "salmon4" "sandybrown" "seagreen" "seagreen1"
## [576] "seagreen2" "seagreen3" "seagreen4" "seashell" "seashell1"
## [581] "seashell2" "seashell3" "seashell4" "sienna" "sienna1"
## [586] "sienna2" "sienna3" "sienna4" "skyblue" "skyblue1"
## [591] "skyblue2" "skyblue3" "skyblue4" "slateblue" "slateblue1"
## [596] "slateblue2" "slateblue3" "slateblue4" "slategray" "slategray1"
## [601] "slategray2" "slategray3" "slategray4" "slategrey" "snow"
## [606] "snow1" "snow2" "snow3" "snow4" "springgreen"
## [611] "springgreen1" "springgreen2" "springgreen3" "springgreen4" "steelblue"
## [616] "steelblue1" "steelblue2" "steelblue3" "steelblue4" "tan"
## [621] "tan1" "tan2" "tan3" "tan4" "thistle"
## [626] "thistle1" "thistle2" "thistle3" "thistle4" "tomato"
## [631] "tomato1" "tomato2" "tomato3" "tomato4" "turquoise"
## [636] "turquoise1" "turquoise2" "turquoise3" "turquoise4" "violet"
## [641] "violetred" "violetred1" "violetred2" "violetred3" "violetred4"
## [646] "wheat" "wheat1" "wheat2" "wheat3" "wheat4"
## [651] "whitesmoke" "yellow" "yellow1" "yellow2" "yellow3"
## [656] "yellow4" "yellowgreen"24.2.6 Describe Interval & Ratio (Continuous) Variables
We can describe variables with interval or ratio measurement scales (i.e., continuous variables) by computing measures of central tendency (e.g., mean, median) and dispersion (e.g., standard deviation, range); however, it’s often good practice to begin by creating data visualizations (e.g., histograms, box plots) that will enable us to understand the nature of each variable’s distribution.
24.2.6.1 Create Data Visualizations
By visualizing the shape of a continuous variable’s distribution (e.g., normal distribution, positive skew, negative skew), we can make a more informed decision regarding how to select, interpret, and report measures of central tendency and dispersion. In this section, we’ll focus on creating histograms and box plots.
Create Histograms: A histogram visually approximates the distribution of a set of numerical scores. The scores are grouped into ranges (which by default are often equally sized), and the boundaries of these ranges are referred to as breaks or break points. The bars in a histogram fill these ranges, and their heights represent the frequency (i.e., count) of sources within each range.
Let’s begin with the Age variable. To create a histogram, we can use the hist function from base R. To get things started, let’s enter a single argument: the name of the data frame object (demo), followed by the $ operator and the name of the variable we wish to visualize (Age).
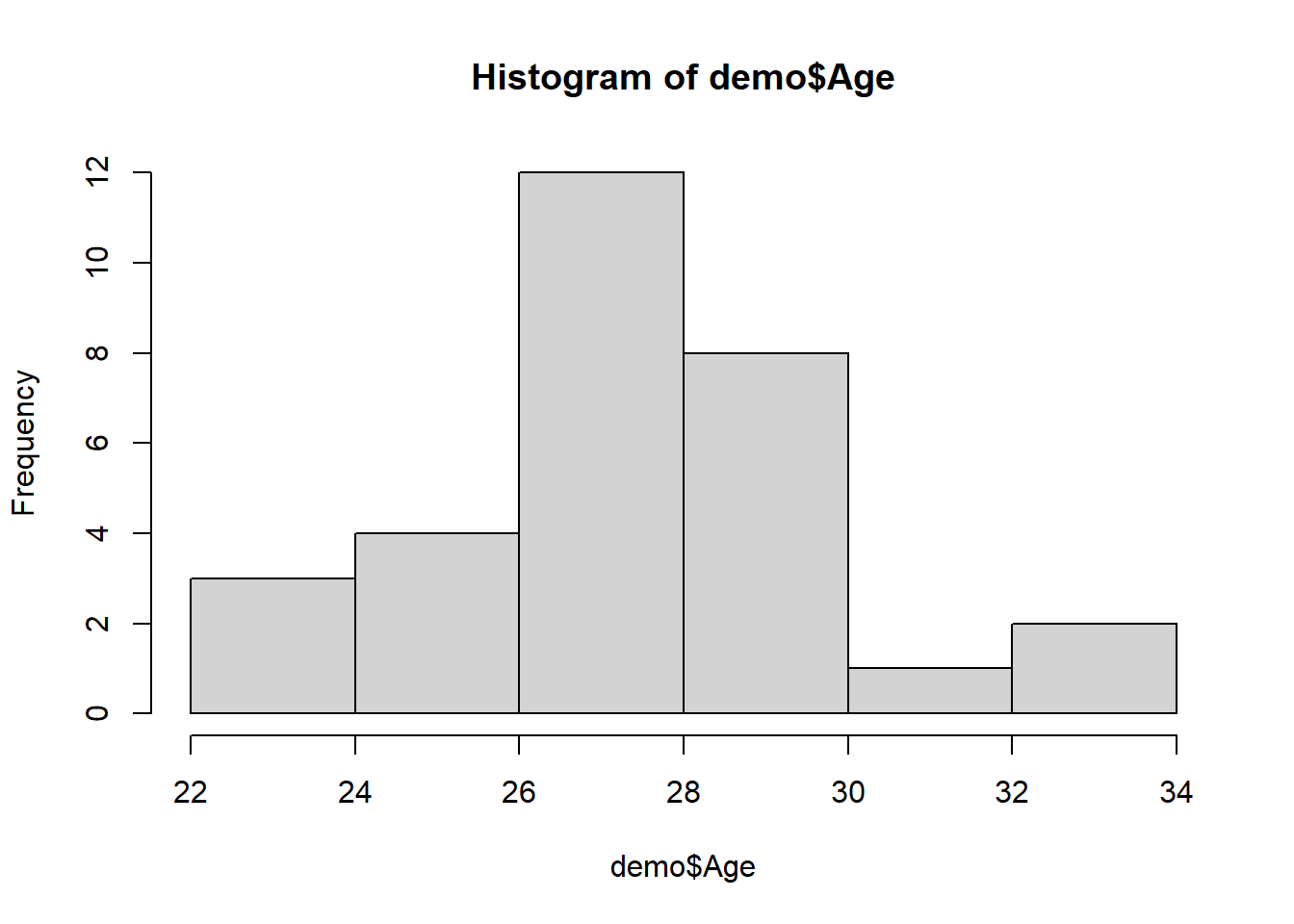
This histogram will do just fine for our purposes. Note that the histogram indicates that the scores from the Age variable appear to be roughly normally distributed. With smaller sample sizes (e.g., fewer than 30 observations or cases), we’re less likely to see a clean, normal distribution of scores, and this relates to the central limit theorem; though, an explanation of this theorem is beyond the scope of this tutorial. Nevertheless, the take-home message is that histograms provide rough approximations of the shapes of distributions, and a normal distribution is less likely when their are fewer observations (i.e., a smaller sample) and thus fewer scores on a variable.
For your own internal data-exploration purposes, it is often fine to create a simple histogram like the one we created above, meaning that you would not need to worry about the aesthetics (e.g., size, color) of the histogram. If you want, you can export this plot as a PDF or PNG image file, or you can copy it and paste it in another document. To do so, just click on the Export button in the Plots window, which should appear in the lower right of your RStudio interface.
As optional next steps, you can play around with arguments to adjust the y-axis limits (ylim), x-axis label (xlab), y-axis label (ylab), main title (main), and the bar color (col). [If you’d like to explore additional colors, check out this website: https://www.r-graph-gallery.com/colors.html. Or, you can run the colors() function (without any arguments), and you’ll get a (huge) list of the color options.] A more in-depth description of these plot arguments is provided in the section above called Create Bar Charts.
# Create a histogram and add style
hist(demo$Age,
ylim=c(0, 15), # y-axis limits
xlab="Employee Age", # x-axis label
ylab="Count", # y-axis label
main=NULL, # main title
col="dodgerblue") # bar color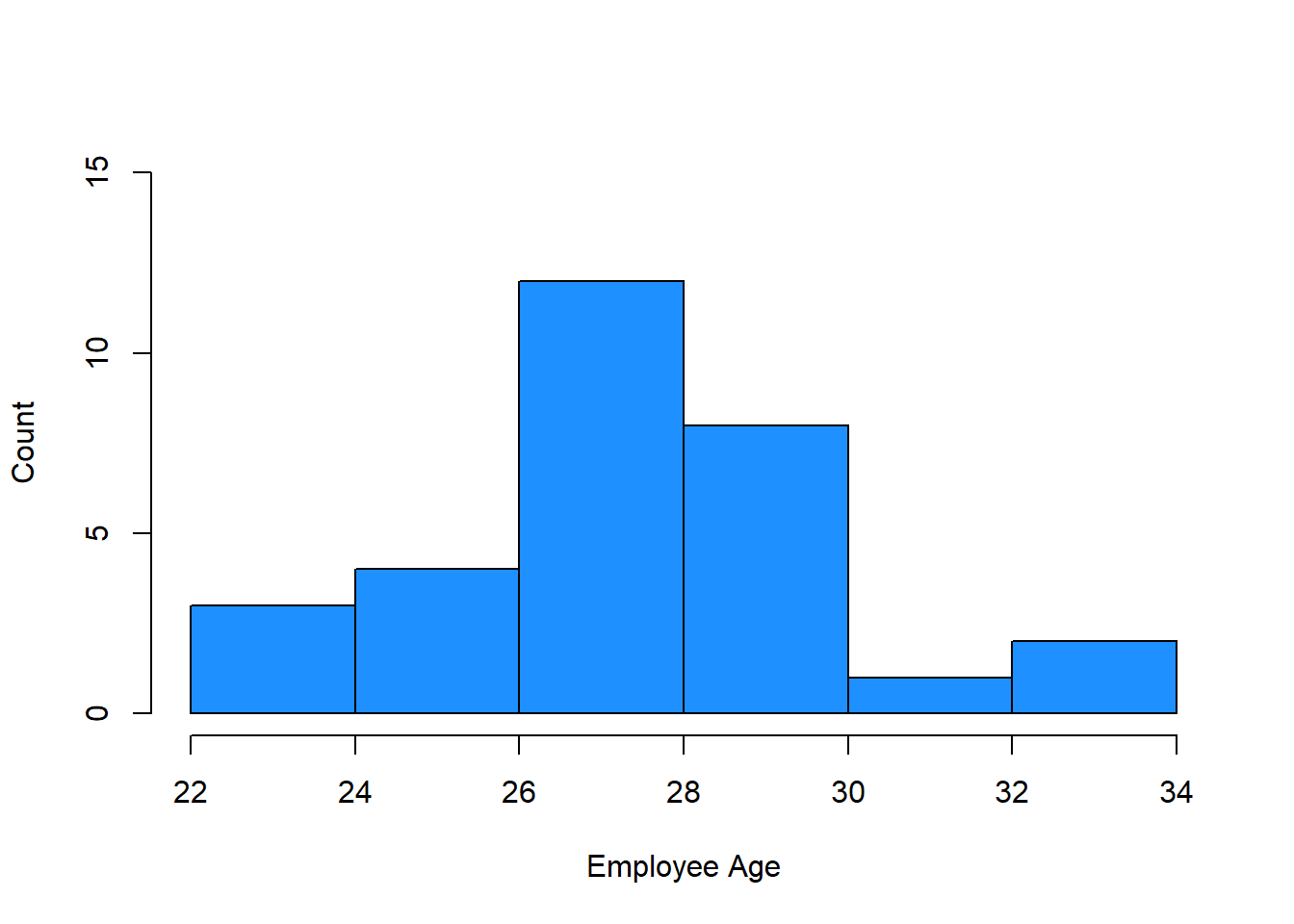
We can also specify a vector of the break points between the bars using the c function from base R. Just be sure that the lowest value in your vector is equal to or less than the minimum value for the variable and the the highest value is equal to or greater than the maximum value for the variable. To do so, we can add the breaks argument.
# Create a histogram and add style
hist(demo$Age,
ylim=c(0, 25), # y-axis limits
xlab="Employee Age", # x-axis label
ylab="Count", # y-axis label
main=NULL, # remove main title
col="dodgerblue", # bar color
breaks=c(20, 25, 30, 35)) # set break points between bars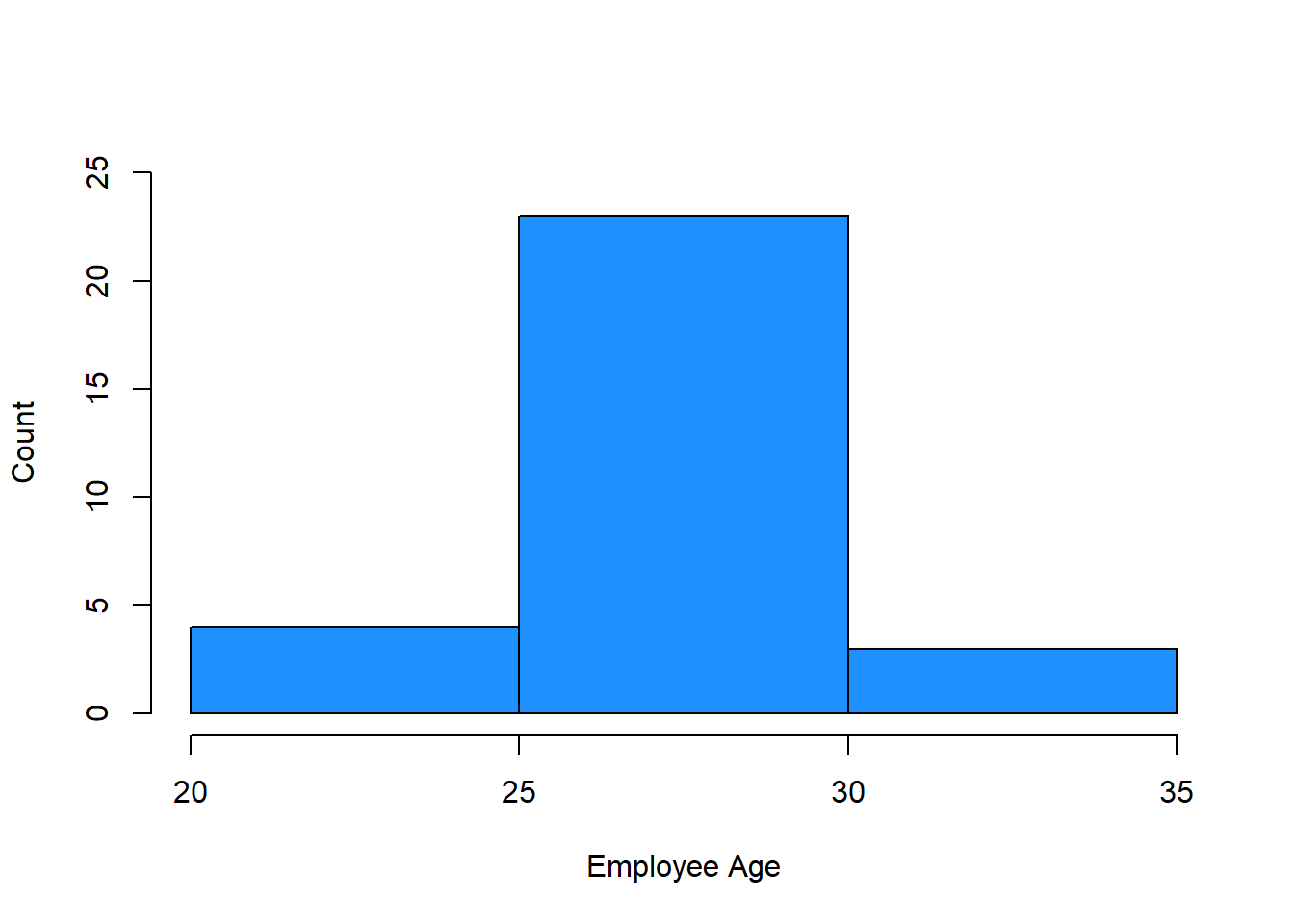
Create Box Plots: We could use a histogram to visualize the Performance variable, but let’s use this opportunity to create a box plot instead. Like a histogram, a box plot (sometimes called a “box and whiskers plot”) also reveals information about the shape of a distribution, including the median, 25th percentile (i.e., lower quartile), 75th percentile (i.e., upper quartile), and the variation outside the 25th and 75th percentiles.
We’ll use the boxplot function from base R. To kick things off, let’s enter a single argument: the name of the data frame object (demo), followed by the $ operator and the name of the variable we wish to visualize (Performance).
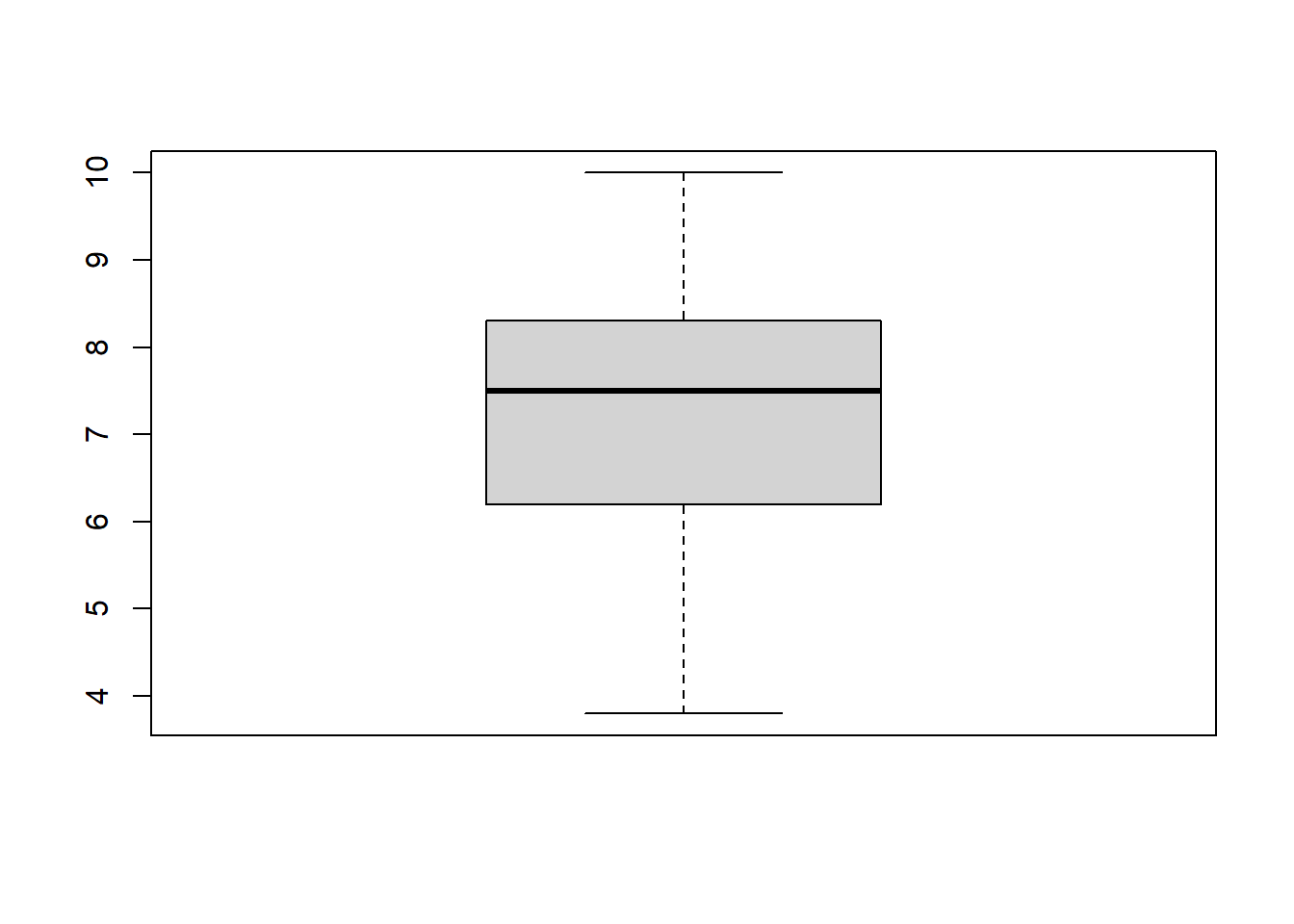
The thick horizontal line in the middle of the box is the median score, the lower edge of the box represents the lower quartile (i.e., 25th percentile, median of lower half of the distribution), and the upper edge of the box represents the upper quartile (i.e., 75th percentile, median of the upper half of the distribution). The height of the box is the interquartile range. By default, the boxplot function sets the upper “whisker” (i.e., the horizontal line at the top of the upper dashed line) as the smaller of two values: the maximum value or 1.5 times the interquartile range. Further, the function sets the lower “whisker” (i.e., the horizontal line at the bottom of the lower dashed line) as the larger of two values: the minimum value or 1.5 times the interquartile range.
In the box plot for Performance, we can see that the distribution of scores appears to be slightly negatively skewed, as the upper quartile is smaller than the lower quartile (i.e., the median is closer to the top of the box) and the upper whisker is shorter than the lower whisker. If there had been any outlier scores, these would appear beyond the upper and lower limits of the whiskers.
If you plan to create a box plot for your own data-exploration purposes only, it is often fine to create a simple box plot like the one we created above, which means you would not need to proceed forward with subsequent steps in which I show how to refine the aesthetics of the box plot. If you want, you can export this plot as a PDF or PNG image file, or you can copy it and paste it in another document. To do so, just click on the Export button in the Plots window, which should appear in the lower right of your RStudio interface.
As optional next steps, you can play around with arguments to adjust the y-axis label (ylab) and the box color (col). If you’d like to explore additional colors, check out this website. Or, you can run the colors() function (without any arguments), and you’ll get a (huge) list of the color options.
# Create a box plot and add style
boxplot(demo$Performance,
ylab="Employee Job Performance", # y-axis label
col="orange") # bar color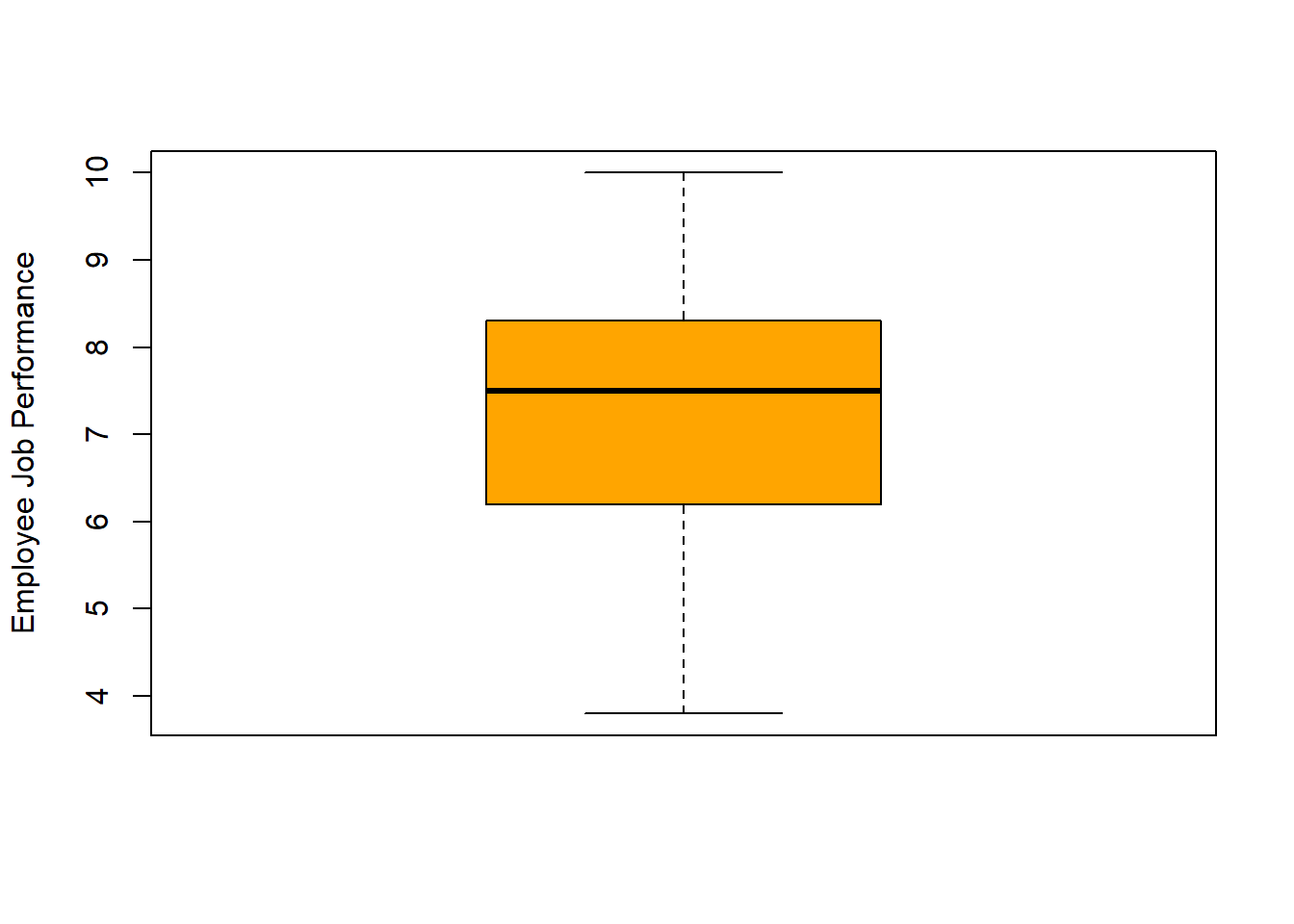
24.2.6.2 Compute Measures of Central Tendency & Dispersion
Now that we’ve visualized our interval and ratio measurement scale variables, we’re ready to compute some measures of central tendency and dispersion. In R the process is quite straightforward, as the function names are fairly intuitive: mean (mean), var (variance), sd (standard deviation), median (median), min (minimum), max (maximum), range (range), and IQR (interquartile range). Within each function’s parentheses, you will enter the same arguments. Specifically, you should include the name of the data frame (demo), followed by the $ operator and the name of the variable ofese measures of central tendency even if there are missing data for the varia interest (Age). Keep the na.rm=TRUE argument as is if you would like to calculate the variable of interest.
Let’s start with some measures of central tendency for the Age variable, specifically the mean (mean) and median (median).
## [1] 28## [1] 28As you can, see both the median and the mode happen to be 28, which indicates that center of the Age distribution is about 28 years. Should we have a skewed distribution (positive or negative), the median is often a better indicator of central tendency given that it is less susceptible to influential cases (e.g., outliers). A class example of a skewed distribution in organizations involves pay variables, especially when executive pay is included. In U.S. organizations, executive pay often is far greater than average worker’s pay, which often leads us to report the median pay as an indicator of central tendency.
Let’s move on to some measures of dispersion, specifically the variance (var) and standard deviation (sd).
## [1] 7.103448## [1] 2.665229The variance is a nonstandardized indicator of dispersion or variation, so we typically interpret the square root of the variance, which is called the standard deviation. Given that we found a mean age of 28 years for this sample of employees, the standard deviation of approximately 2.67 years indicates that approximately 68% of employees’ ages fall within 2.67 years (i.e., 1 SD) of 28 years (i.e., between 25.33 and 30.67 years), and 95% of employees’ ages fall within 5.34 years (i.e., 2 SD) of 28 years (i.e., between 22.66 and 33.34 years). As we saw in the histogram for Age, the variable has a roughly normal distribution.
Let’s compute the minimum and maximum score for Age using the min and max functions, respectively.
## [1] 22## [1] 34The minimum age is 22 years for this sample, and the maximum age is 34 years.
Next let’s compute the range, which will give us the minimum and maximum scores using a single function.
## [1] 22 34As you can see, the range functions provides both the minimum and maximum scores.
Next, let’s compute the interquartile range (IQR), which is the distance between the lower and upper quartiles (i.e., between the 25th and 75th percentile). As noted above in the section called Create Box Plots, the lower and upper quartiles correspond to the outer edges of the box, whereas the median (50th percentile) corresponds to the line within the box.
## [1] 3The IQR is 3 years, which indicates that middle 50% of ages spans 3 years.
As a follow-up, let’s compute the lower and upper quartiles (i.e., between the 25th and 75th percentiles) by using the quantile function from base R. As the first argument, type the name of the data frame (demo), followed by the $ operator and the name of the variable of interest (Age). As the second argument, type .25 if you would like to request the 25th percentile (lower quartile) and .75 if you would like to request the 75th percentile (upper quartile). Let’s do both.
## 25%
## 27## 75%
## 30Corroborating what we found with the IQR, the difference between the upper and lower quartiles is 3 years (30 - 27 = 3).
The IQR and lower and upper quartiles are typically reported along with the median (as evidenced by the box plot we created above), so let’s report them together. If you recall, the median age was 28 years for this sample, and the IQR spans 3 years from 27 years to 30 years. These measures indicate that the middle 50% of ages for this sample are between 27 and 30 years, and that the middle-most age (i.e., 50th percentile) is 28 years.
Alternatively, if we wish to automatically compute the 0th, 25th, 50th, 75th, and 100th percentile all at once, we can simply type the name of the quantile function and then enter the name of the data frame object (df) followed by the $ operator and the name of the variable (Age).
## 0% 25% 50% 75% 100%
## 22 27 28 30 34Finally, one way to compute the minimum, lower quartile (1st quartile), median, mean, upper quartile (3rd quartile), and maximum all at once is to use the summary function from base R with the name of the data frame object (demo) followed by the $ operator and the name of the variable (Age) as the sole parenthetical argument.
# Minimum, lower quartile (1st quartile), median, mean, upper quartile (3rd quartile), and maximum
summary(demo$Age)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 22 27 28 28 30 3424.2.7 Summary
In this chapter, we focused on descriptive statistics. First, we began by learning about four different measurements scales (i.e., nominal, ordinal, interval, ratio) and how identifying the measurement scale of a variable is an important first step in determining an appropriate descriptive statistic or data-visualization display type. Second, we learned how to compute counts (i.e., frequencies) for nominal and ordinal variables using the table function from base R. Further, you learned how to convert a variable to an ordered factor using the factor function from base R. Finally, you learned how to visualize counts data using the barplot function from base R. Finally, we learned how to visualize the distribution of a variable with an interval or ratio measurement scale using histograms (hist function from base R) and box plots (boxplot function from base R). In addition, we learned how to compute measures of central tendency and dispersion base R functions like mean (mean), var (variance), sd (standard deviation), median (median), min (minimum), max (maximum), range (range), and IQR (interquartile range).
24.3 Chapter Supplement
In this chapter supplement, we will learn how to compute the coefficient of variation (CV).
24.3.2 Initial Steps
If required, please refer to the Initial Steps section from this chapter for more information on these initial steps.
# Access readr package
library(readr)
# Read data and name data frame (tibble) object
demo <- read_csv("employee_demo.csv")## Rows: 30 Columns: 5
## ── Column specification ────────────────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (3): EmpID, Facility, Education
## dbl (2): Performance, Age
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## [1] "EmpID" "Facility" "Education" "Performance" "Age"24.3.3 Compute Coefficient of Variation (CV)
The coefficient of variation (CV) (also known as relative standard deviation) is a standardized indicator of dispersion that can be used to compare the relative variability of two or more variables with different scaling. Technically, it is really only appropriate and meaningful to compute the CV for variables that have a ratio measurement scale and thus a meaningful zero; however, sometimes people relax this assumption (albeit inappropriately) to allow for the CV to be computed for a variable with an interval measurement scale. I urge you to only compute CVs for variables with ratio measurement scales.
As a hypothetical application of the CV, imagine you would like to compare the variability of these two measures – both having a ratio measurement scale: (a) monthly base pay measured in US dollars, and (b) monthly variable pay measured in US dollars.
The formula to compute the CV for a variable is simple. In fact, it’s just the ratio of a variable’s standard deviation (SD) relative to its mean, which results in a proportion. If we multiply that proportion by 100, we can interpret the CV as a percentage.
\(CV = \frac{SD}{mean} * 100\)
Let’s imagine that for a given sample of employees the mean monthly base pay is 3,553 dollars, and the SD is 593 dollars. Further, the mean monthly variable pay for these same employees is 422 dollars, and the SD is 98 dollars. Let’s compute the CV for each measure and then compare.
\(CV_{basepay} = \frac{593}{3553} * 100 = 16.7\)
\(CV_{variablepay} = \frac{98}{422} * 100 = 23.2\)
Note that the CV for monthly base pay is 16.7%, and the CV for the monthly variable pay is 23.2%. We can interpret these descriptively as indicating that monthly variable pay shows higher variability around its mean relative to monthly base pay. In other words, monthly variable pay shows higher relative dispersion than monthly base pay. It’s important to note that comparing CVs in this way is entirely descriptive, which means that we cannot conclude that the two CVs differ significantly from one another in a statistical sense; to make such a conclusion, we would need to estimate an appropriate inferential statistical analysis (Feltz and Miller 1996; Lewontin 1966; Miller 1991).
Alternatively, CVs can be computed to compare the relative variability of the same measure assessed with two independent samples. For example, in a clinical setting, the CV for a measure can be computed for each clinical trial sample in which it was administered to evaluate whether it’s appropriate to combine data from multiple samples.
Now that we understand what a coefficient of variation is, let’s practice computing one by using the data frame we read in called called demo. Note that both the Performance and Age variables can be described as having interval and ratio measurement scales, respectively.
Let’s begin by computing the coefficient of variation (CV) for the Performance variable. As noted in the introduction, the formula is simply a ratio, such that we divide the standard deviation (SD) for the measure by the mean for that measure. We can then convert the resulting proportion to a percentage by multiplying the proportion by 100. To compute the SD, we’ll use the sd function from base R, and to compute the mean, we’ll use the mean function from base R. Within each function, we enter the name of the data frame object (demo) followed by the $ operator and the name of the variable in question that belongs to the aforementioned data frame object. To divide we use the forward slash (/), and to multiply we use the asterisk (*), as shown below.
# Compute coefficient of variation (CV) for Performance variable
sd(demo$Performance) / mean(demo$Performance) * 100## [1] 21.15746In the Console, we should see that the CV for the Performance variable is approximately 21.2%.
Next, let’s compute the CV for the Age variable. We’ll use the same formula as above, except swap out the Performance variable for the Age variable.
## [1] 9.518677In the Console, we should see that the CV for the Age variable is approximately 9.5%.
As noted in the introduction, we are being descriptive in our comparisons in this tutorial and are not applying an inferential statistical analysis. Given that, we cannot make statements indicating that one CV is significantly larger than the other. To make such a statement, we would need to apply an inferential statistical analysis (Lewontin 1966; Miller 1991), which is beyond the scope of this chapter on descriptive statistics.