Chapter 38 Estimating Criterion-Related Validity of a Selection Tool Using Correlation
In this chapter, we will learn how to estimate the criterion-related validity of an employee selection tool by using a correlation. We’ll begin with a conceptual overview of criterion-related validity and correlation, and we’ll conclude with a tutorial.
38.2 Tutorial
This chapter’s tutorial demonstrates how to estimate criterion-related validity using a correlation, and how to present the results in writing.
38.2.4 Visualize Association Using a Scatter Plot
Two of the key statistical assumptions that should be satisfied prior to estimating a Pearson product-moment correlation are that (a) the association between the two variables is approximately linear and that (b) a bivariate normal distribution exists between the two variables. A data visualization called a scatter plot can be used to test both of these assumptions.
The ScatterPlot function from the lessR package (Gerbing, Business, and University 2021) does a nice job generate generating scatter plots – and it even provides an estimate of the correlation by default. If you haven’t already, install and access the lessR package.
To begin, type the name of the ScatterPlot function. As the first two arguments of the function, type the names of the two variables you wish to visualize; let’s start by visualizing the association between the Conscientiousness selection tool and the criterion (Performance). The variable name that we type after the x= argument will set the x-axis, and the variable name that we type after the y= argument will set the y-axis. Conventionally, we place the criterion variable on the y-axis, as it is the outcome. As the third argument, use the data= argument to provide the name of the data frame to which the two variables belong (df).
# Create scatter plot using ScatterPlot function from lessR
ScatterPlot(x=Conscientiousness, y=Performance, data=df)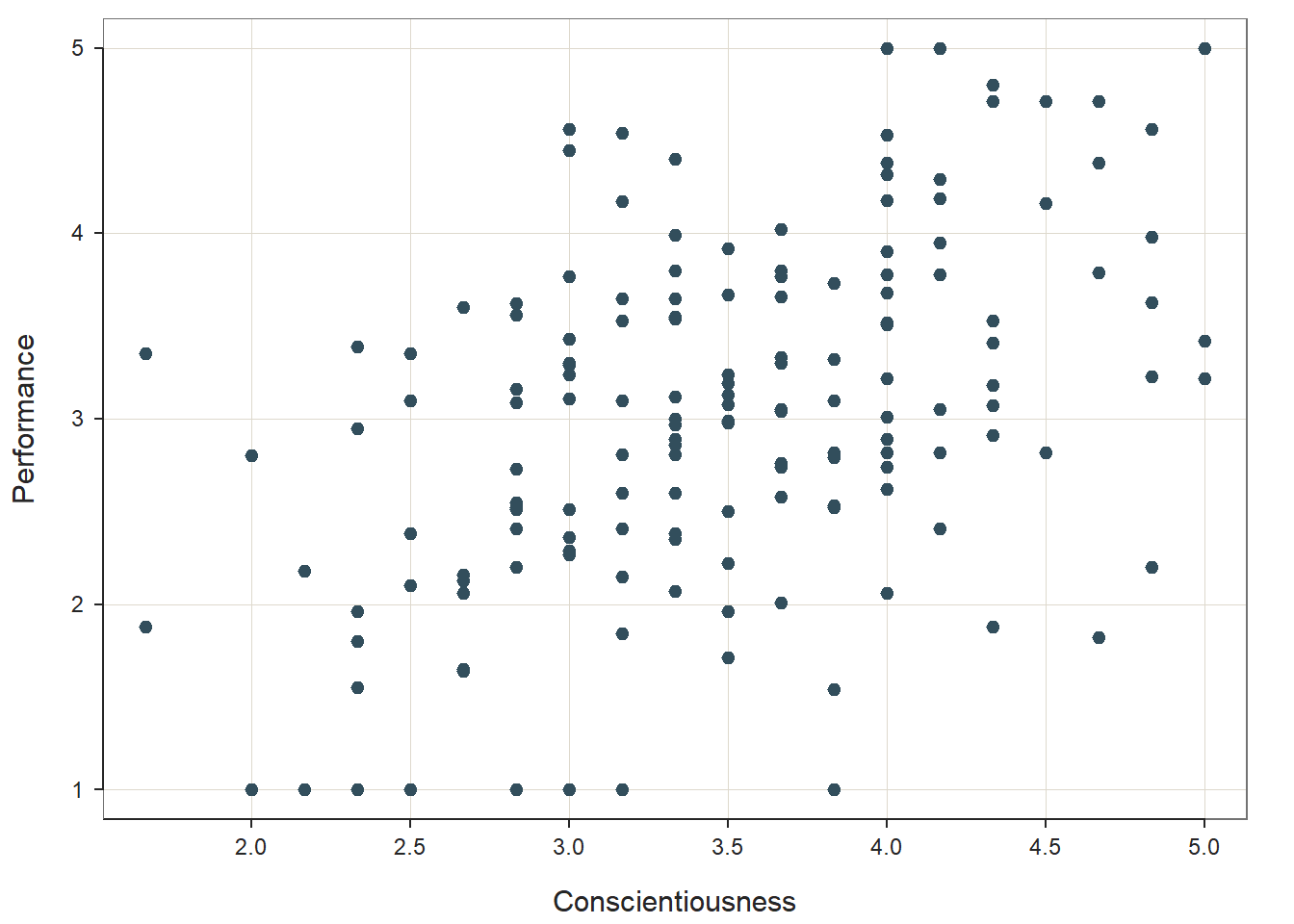
## --- Pearson's product-moment correlation ---
##
## Number of paired values with neither missing, n = 163
## Sample Correlation of Conscientiousness and Performance: r = 0.469
##
## Hypothesis Test of 0 Correlation: t = 6.732, df = 161, p-value = 0.000
## 95% Confidence Interval for Correlation: 0.339 to 0.581
## In our plot window, we can see a fairly clear positive linear trend between Conscientiousness and Performance, which provides us with some evidence that the assumption of a linear association has been satisfied. Furthermore, the distribution is ellipse-shaped, which gives us some evidence that the underlying distribution between the two variables is likely bivariate normal – thereby satisfying the second assumption mentioned above. Note that the ScatterPlot function automatically provides an estimate of a (Pearson product-moment) correlation in the output (r = .509), along with the associated p-value (p < .001).
38.2.4.1 Optional: Stylizing the ScatterPlot Function from lessR
If you would like to optionally stylize your scatter plot, we can use the xlab= and ylab= arguments to change the default names of the x-axis and y-axis, respectively.
# Optional: Styling the scatter plot
ScatterPlot(x=Conscientiousness, y=Performance, data=df,
xlab="Conscientiousness Test Score",
ylab="Job Performance Score")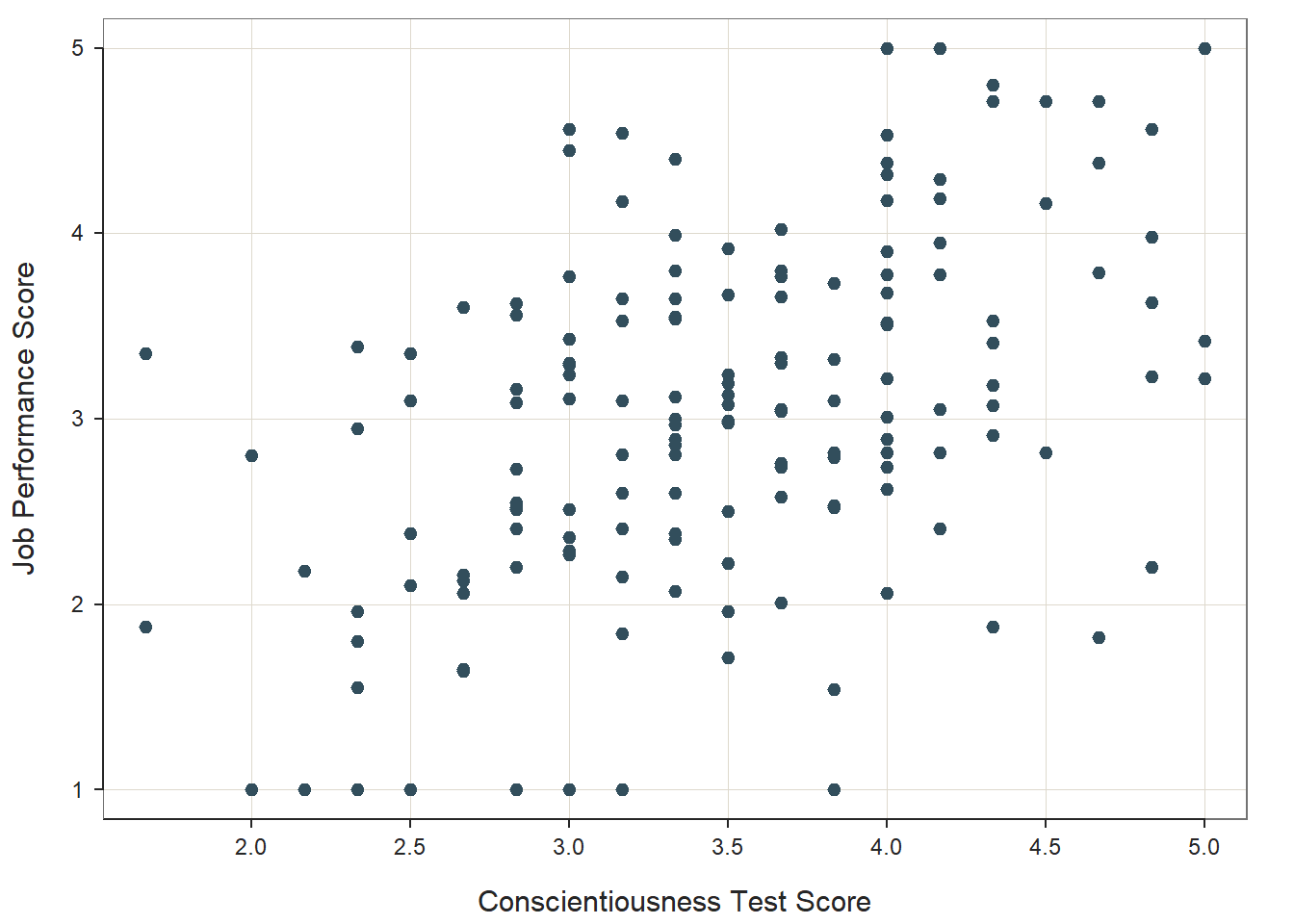
## --- Pearson's product-moment correlation ---
##
## Number of paired values with neither missing, n = 163
## Sample Correlation of Conscientiousness and Performance: r = 0.469
##
## Hypothesis Test of 0 Correlation: t = 6.732, df = 161, p-value = 0.000
## 95% Confidence Interval for Correlation: 0.339 to 0.581
## We can also superimpose an ellipse by adding the argument ellipse=TRUE, which can visually aid our judgument on whether the distribution is bivariate normal.
# Scatterplot using ScatterPlot function from lessR
ScatterPlot(x=Conscientiousness, y=Performance, data=df,
xlab="Conscientiousness Test Score",
ylab="Job Performance Score",
ellipse=TRUE)## [Ellipse with Murdoch and Chow's function ellipse from their ellipse package]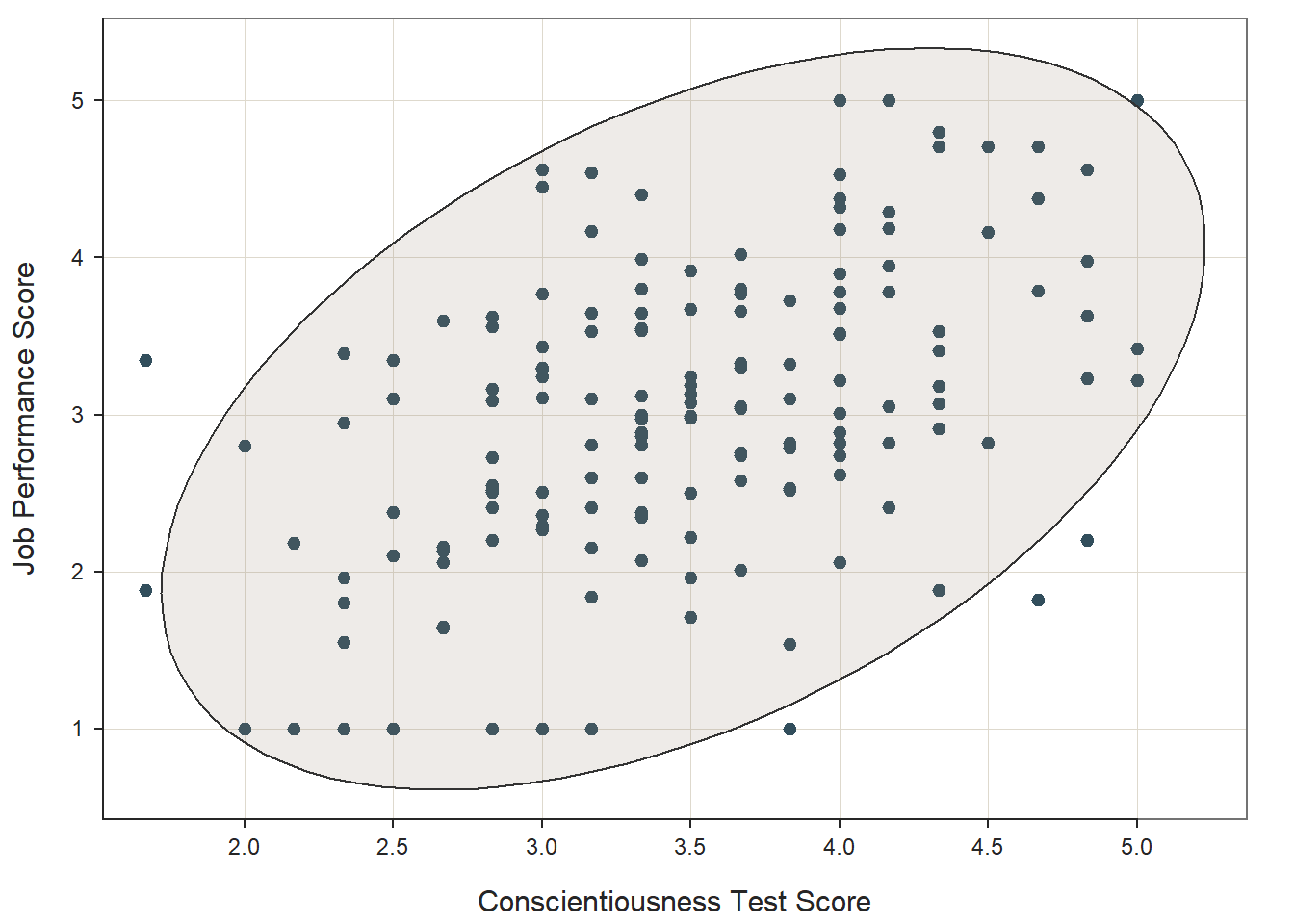
## --- Pearson's product-moment correlation ---
##
## Number of paired values with neither missing, n = 163
## Sample Correlation of Conscientiousness and Performance: r = 0.469
##
## Hypothesis Test of 0 Correlation: t = 6.732, df = 161, p-value = 0.000
## 95% Confidence Interval for Correlation: 0.339 to 0.581
## 38.2.5 Estimate Correlation
Important note: For space considerations, we will assume that the variables we wish to correlate have met the necessary statistical assumptions (see Statistical Assumptions section). For instance, we will assume that employees in this sample were randomly drawn from the underlying population of employees, that there is evidence of univariate and bivariate normal distributions for the variables in question, that the data are free of outliers, and that the association between variables is linear. To learn how to create a histogram or VBS plot (violin-box-scatter plot) to estimate the shape of the univariate distribution for each variable and to flag any potential univariate outliers, which can be used to assess the assumptions of univariate normal distribution and absence of univariate outliers, check out the chapter called Descriptive Statistics.
There are different functions we could use to estimate a Pearson product-moment correlation between two variables (or a biserial correlation). In this chapter, I will demonstrate how to use the Correlation function from the lessR package.
If you haven’t already, install and access the lessR package using the install.packages and library functions, respectively (see above).
To begin, type the name of the Correlation function from the lessR package. As the first two arguments of the function, type the names of the two variables you wish to visualize; let’s start by visualizing the association between the Conscientiousness selection tool and the criterion (Performance). Conventionally, the variable name that appears after the x= argument is our predictor (e.g., selection tool), and the variable name that appears after the y= argument is our criterion (e.g., job performance). As the third argument, use the data= argument to provide the name of the data frame to which the two variables belong (df).
# Estimate correlation using Correlation function from lessR
Correlation(x=Conscientiousness, y=Performance, data=df)## Correlation Analysis for Variables Conscientiousness and Performance
##
## --- Pearson's product-moment correlation ---
##
## Number of paired values with neither missing, n = 163
## Number of cases (rows of data) deleted: 0
##
## Sample Covariance: s = 0.324
##
## Sample Correlation: r = 0.469
##
## Hypothesis Test of 0 Correlation: t = 6.732, df = 161, p-value = 0.000
## 95% Confidence Interval for Correlation: 0.339 to 0.581As you can see, we find the following: r = .469, p < .001, 95% CI[.339, .581]. We can interpret the finding as follows: Scores on the conscientiousness test are positively associated with job performance scores to a statistically significant extent (r = .469, p < .001, 95% CI[.339, .581]), such that individuals with higher conscientiousness tend to have higher job performance. How do we know the correlation coefficient is statistically significant? Well, the p-value is less than the conventional alpha cutoff of .05. Given the conventional rules of thumb for interpreting a correlation coefficient as an effect size (see Practical Significance section and table below), we can describe this correlation coefficient of .469 as approximately medium or medium-to-large in magnitude. The point estimate of the correlation coefficient (r = .469) does not directly reflect the sampling error that inevitably affects the estimated correlation coefficient derived from our sample; this is where the confidence interval can augment our interpretation by expressing a range, within which we can be reasonably confident that the true (population) correlation coefficient likely falls. With regard to the 95% confidence interval, it is likely that the range from .339 to .581 contains the true (population) correlation; that is, the true (population) correlation coefficient is likely somewhere between medium and large in magnitude.
| r | Description |
|---|---|
| .10 | Small |
| .30 | Medium |
| .50 | Large |
In the context of selection tool validation, the correlation coefficient between a selection tool and a criterion can be used as an indicator of criterion-related validity. Because the correlation above is statistically significant, this provides initial evidence that the conscientiousness test has sufficiently high criterion-related validity, as it appears to be significantly associated with the criterion of job performance. In this context, we can refer to the correlation coefficient as a validity coefficient. Moreover, the practical significance (as indicated by the effect size) is approximately medium or medium-to-large, given the thresholds mentioned above. Thus, as a selection tool, the conscientiousness test appears to have relatively good criterion-related validity for this population.